
At Ambiata, we have built a next-best-action system for automated decisioning which is currently used in production on a variety of use cases. In this post, we build out the components in the system and outline the capabilities that are needed.
To make an effective next-best-action system that can scale to hundreds of models in production and effectively drive your business or services through automated decision-making, it is necessary to solve for 5 key areas:
- Making sure your purpose is ethical and legal
- Efficient access to data with good governance
- Systematic approaches for your data science team to build reliable models that predict customer behaviours
- A production machine learning framework that enables discrimination of causation from correlation; and
- A monitoring system to check that everything is working as designed.
What is a Next-Best-Action?
A customer or client is interacting with your organisation - either digitally on the web or through an app, or physically through a call or face-to-face interaction. What action should you take next? If an interaction flow has multiple options, which one should you select for this customer? If there is space for just one-more-thing that you might mention, what should it be for this person at this moment?
To give immediate service, particularly where physical interactions are not possible, these decisions must be automated. Previously this would be done by business rules - fixed paths through the forest of interaction points that might, at best, group your customers into a number of segments and guide similar people on similar paths. Now, this is typically done through personalisation driven by machine learning. Every interaction point can be customised based on what you know about the person you are interacting with now, based on the learnings from all the other people who have had this interaction in the past.
A next-best-action system solves these problems using a design pattern - taking an online context from the system the customer is interacting with, supplementing it with internal data, and choosing between sets of actions and options using machine learning algorithms designed to try to have the customer reach the desired outcome.
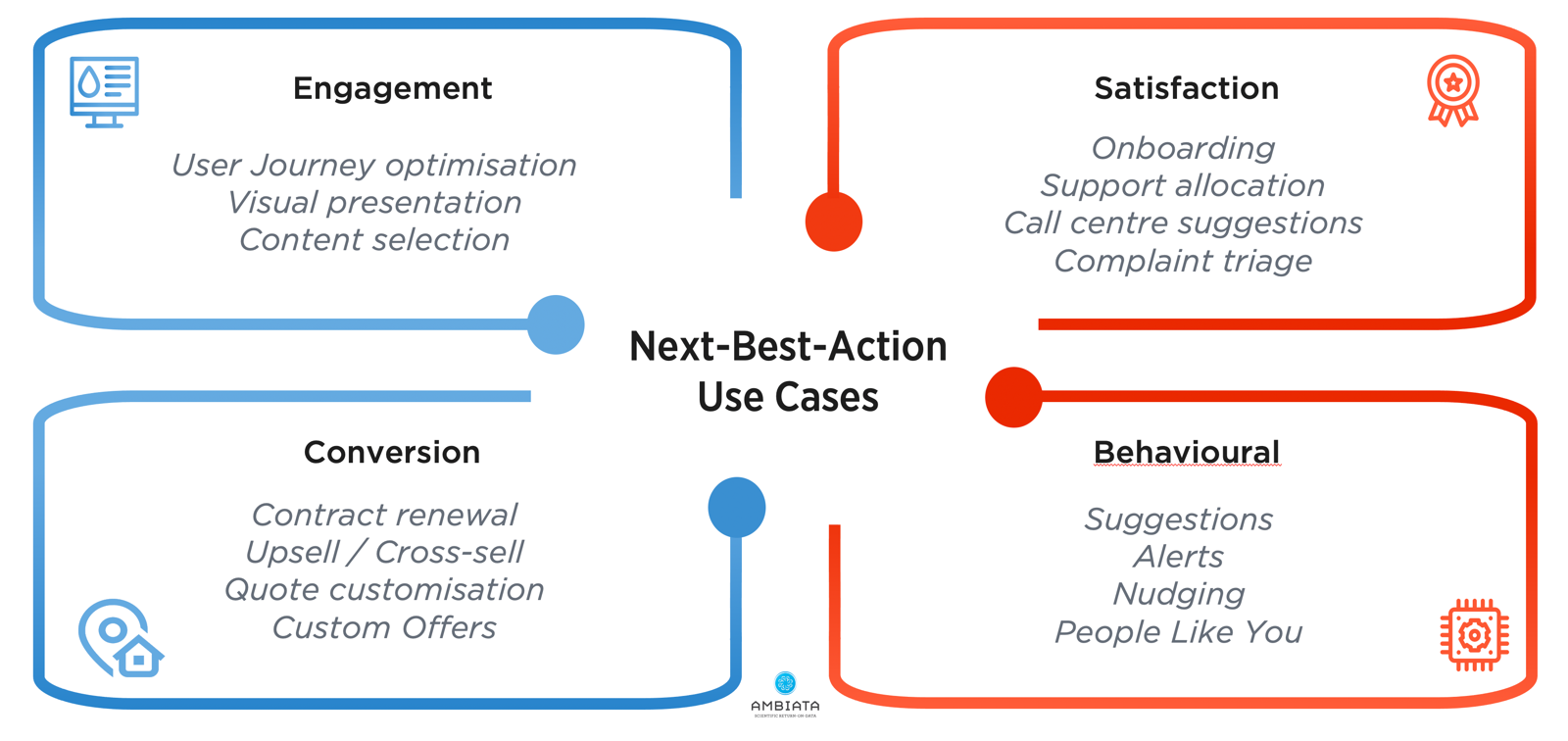
This design pattern can be applied across many different sorts of customer interactions - areas as diverse as deciding what to show people, how to interact with them, what pricing and offers to make them, and what to suggest to them that has the best chance of changing their behaviour.
Steps for implementation
There are capabilities that are necessary to build a scalable next-best-action infrastructure - things like efficient methods of data access and feature generation, an environment for ML modelling, a machine learning deployment framework, and monitoring capabilities to make sure everything is performing as it should. However, before all of that, it is important to understand the ethical positioning of the sorts of actions that may be presented to your customers.
These steps are represented in the following illustration:
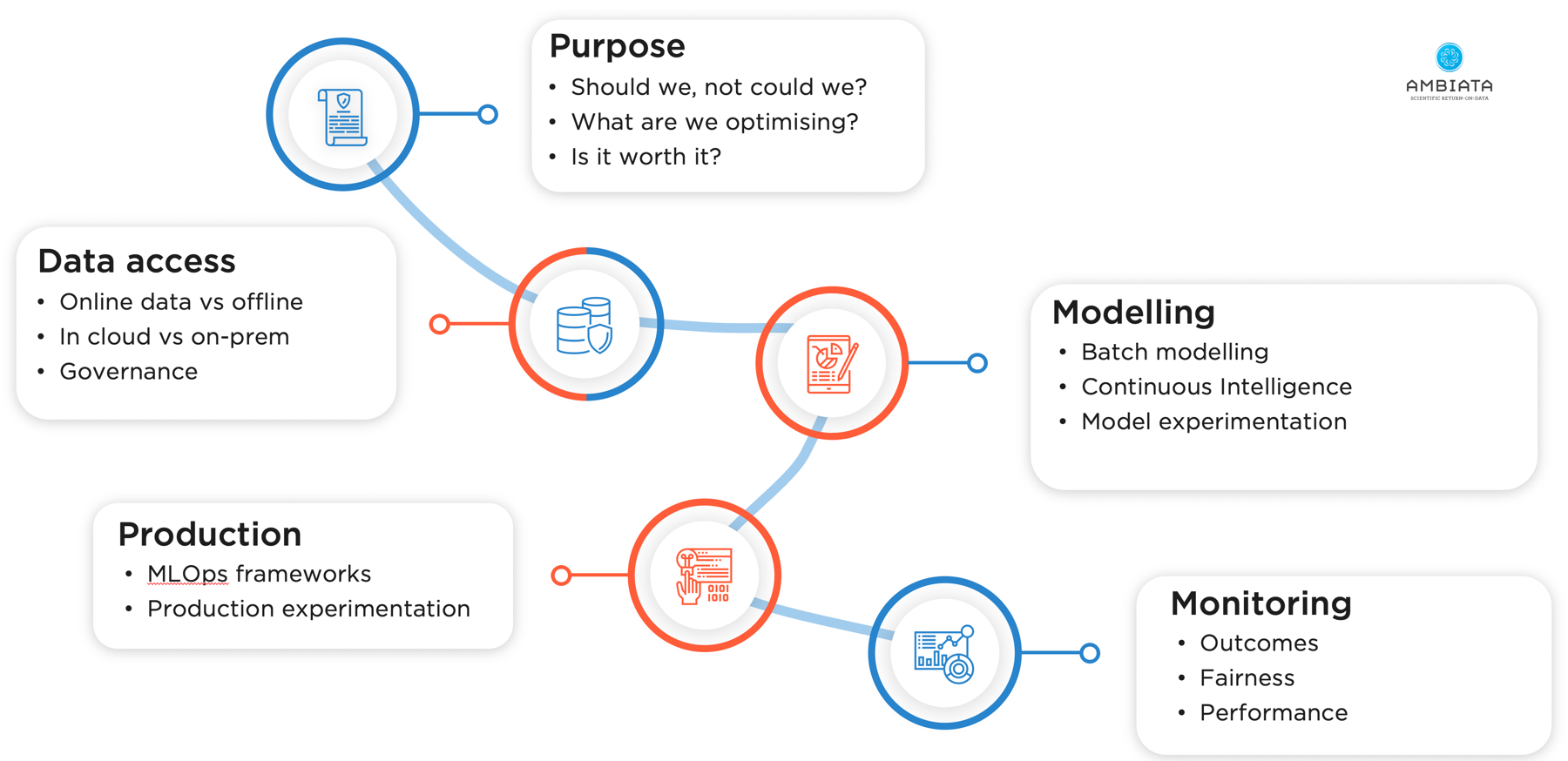
The first step in an automated customer decisioning system is to understand not whether you could do something, but rather whether you should do something. This is the domain of ethics, or more specifically, the ethics of artificial intelligence. In particular, if you are going to use artificial intelligence and machine learning to influence people’s behaviours, it should be clear that you are doing this for the customer’s benefit and that it has a net positive impact on society as a whole.
AI Ethics
Asking “should we”, rather than just “could we”, is one of the principles of the Australian AI Ethics Framework, which outlines 8 principles that should be considered before doing any automated customer decisioning. These principles cover topics such as fairness, privacy, explainability and autonomy, amongst others. It is fundamentally important to consider up-front how any automated decisioning system and associated governance processes address each of these principles to ensure that the system is behaving as expected and not doing any unintentional harm.
Is it worth it?
The second question to ask, after “is this the right thing to do?” is, “is this worth it?”.
Next-best-action recommendation is a form of personalisation - when done properly it can be considered hyper-personalisation. In general, personalisation is only worthwhile if the actions that you are optimising have the following properties:
- When a large enough portion of the user base is dissatisfied by the default action
- When you have data that is predictive of preference, so you can personalise the options.
The last issue is a key consideration, but can be quite subtle - if you don’t have any data that reads on the decision you are going to make, then a well-designed machine learning system can be built to recommend some default actions when it has no evidence to support an alternative action. This means that the system can be designed to fail gracefully towards a set of business rules. At this point, the question can be asked whether it is worthwhile to run the machine learning system at all. However, if the infrastructure is in place, then such systems have up-side potential - as data volume or breadth improves, predictive accuracy may also improve, and the systems will naturally become better at making their decisions. As an aside, it is generally good practice to design automated decisioning systems in this way to cater for any failures that may occur.
What are we optimising?
For any next-best-action system, it is vital to understand what is being targeted by the personalisation system. Machines will do what you tell them - if you give them the wrong target to optimise, they will optimise what you tell them, not what you thought you told them. As a case in point, if you set the goal of your next-best-action system to be to optimise conversions, then it will seek to do that, perhaps at the expense of profit, or customer satisfaction, or employee experience. Due to the implacable nature of algorithmic optimisation, defining what success looks like for a given decision-making point is key to successfully achieving that goal.
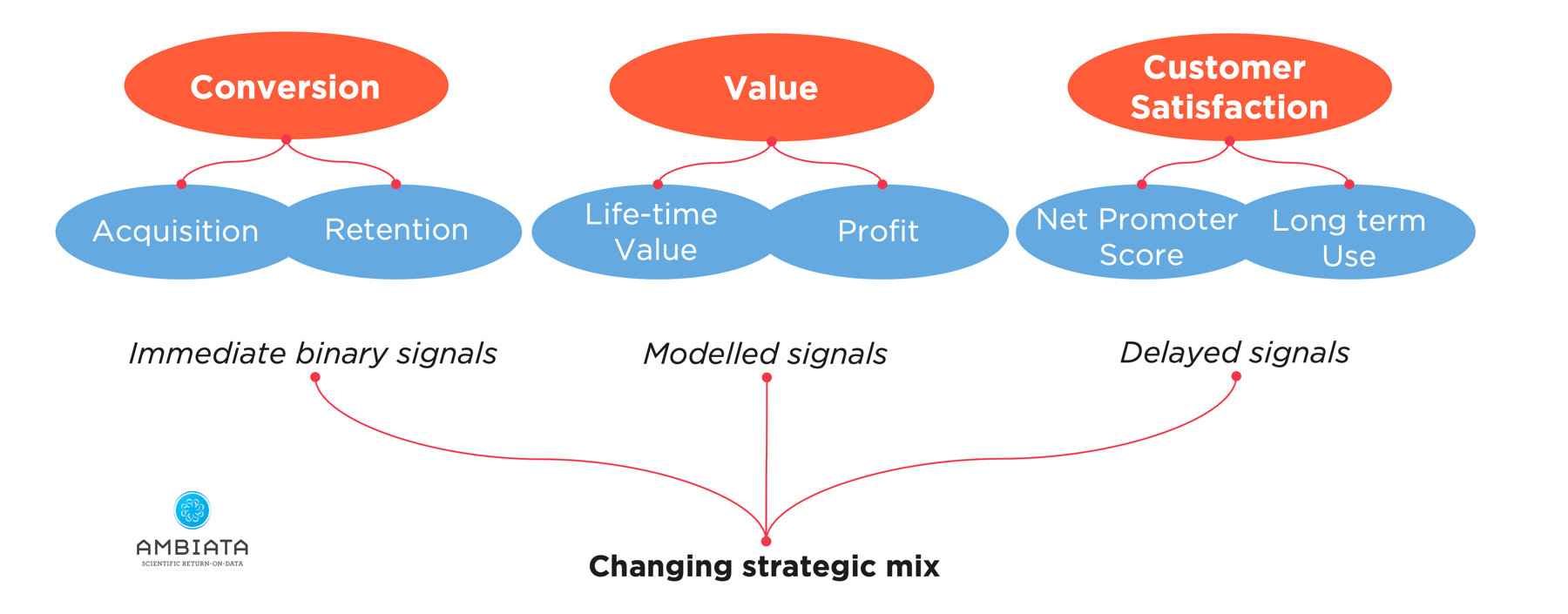
Such optimisation outcomes can also occur on very different time scales:
- Immediate signals such as seeing a customer convert
- Value signals such as short term profit or longer term life-time-value; and
- Customer satisfaction which might be short term, or may generate long-term engagement with your product or service.
While it is generally easier to optimise for short term metrics such as conversion, this is not necessarily the best thing to do. This means that a company might need to invest in building proxies for longer term measures of value, such as life time value.
Example
To make the concept of a next-best-action application more concrete, consider the following form with an offer for a house insurance quote.
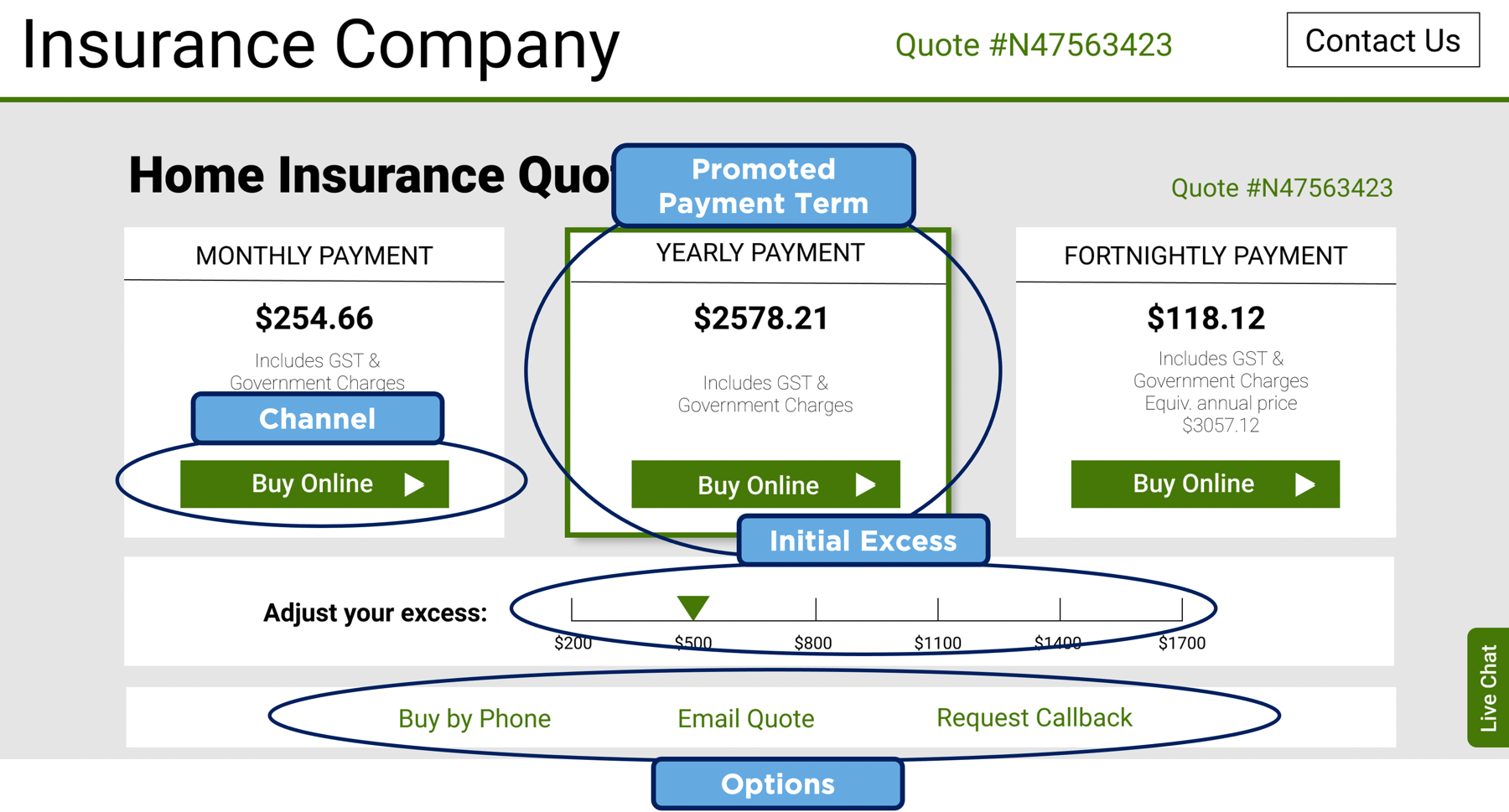
On this page there are a number of options that can be personalised, without changing the basic configuration of the insurance product. These include monthly or yearly payment term, payment channel, the initial excess shown on the slider, and the placement of the various elements on the page. When someone asks for a quote for home insurance, the data provided relating to the quote, and any other data the company holds about that person, or similar people, can be used to change the presentation of the screen to optimise the outcomes the company is looking for.
These sorts of problems are straightforward to solve using modern machine learning techniques, but as has been observed before, typically the machine learning part of a solution is just a small (but important) part of the overall solution.
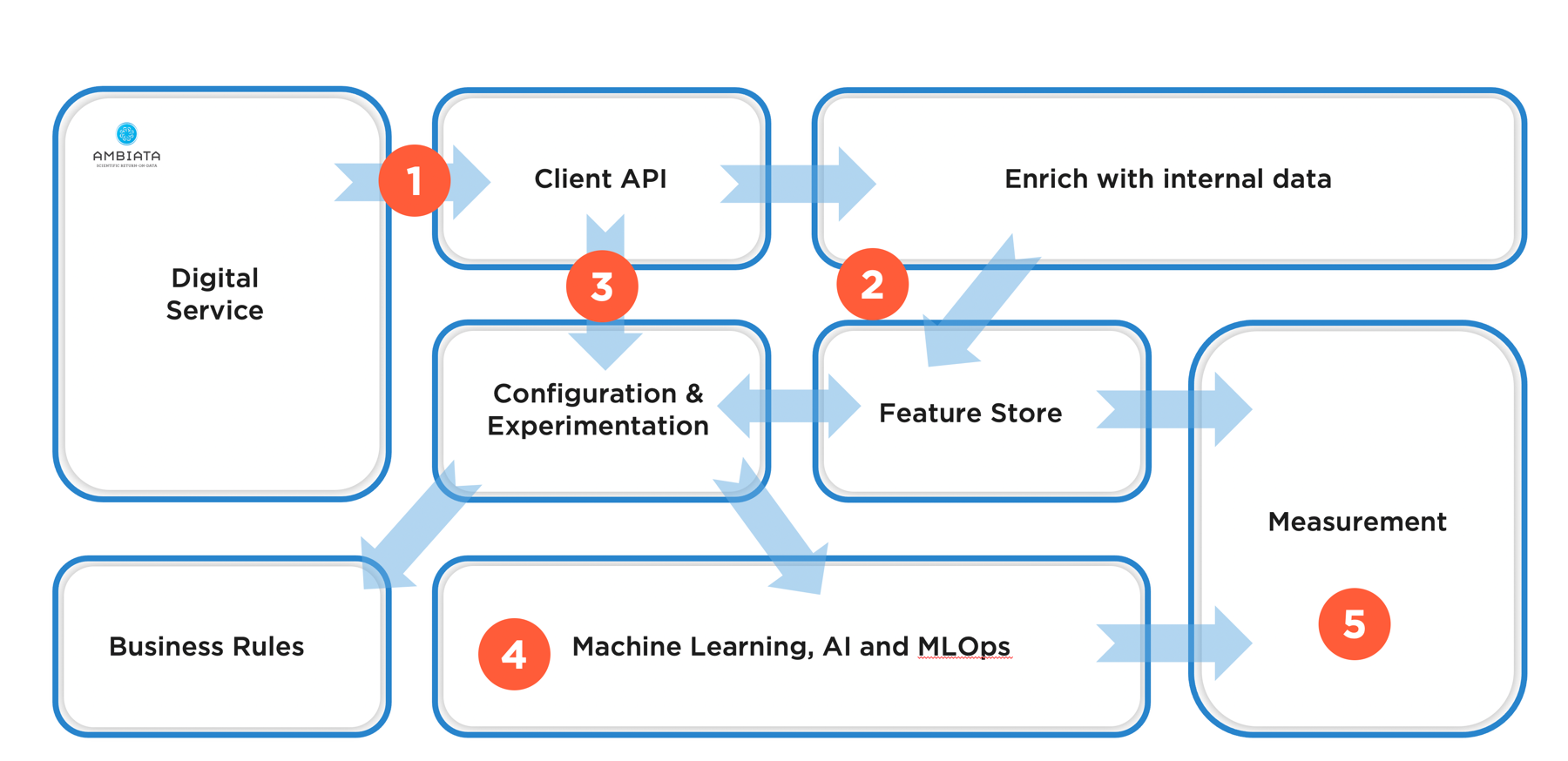
Overview of the architecture
The overall architecture for our next-best-action recommendation system is shown below. There are several key design decisions:
There are two layers of abstraction in the decision-making system, in the first layer the digital service calls an API to get recommended actions and (optionally) feed back the outcomes from customer interaction.
Data passed to the decision-making API from the digital channel can be enriched by data held by the organisation, to give the AI systems more features on which to base its decision.
In the second layer of abstraction, there are APIs for machine learning algorithms and business rules to which different requests can be routed, thereby enabling experimentation and respecting decisions by customers to opt out of automated decisioning.
Data scientists must be enabled to build models and get them into production quickly through an integrated machine learning and MLOps frameworks.
Everything is recorded for measurement, checking for bias in recommendations, and allowing explanations of the decision-making process.
Explicitly mapping this to our example of a home insurance quote page:
The quote page calls the next-best-action API to get the recommended defaults for the quote page, and later feeds back whether the customer moved to the next stage of the quote.
The data about the house insurance quote is passed through the API, and if there is additional data held about the customer (e.g. other policies held, etc), this is added to the data about the request.
The request is routed to either business rules or machine learning algorithms, based on the experimental configuration and the preferences of the user.
If machine learning models have been built and deployed by the data science team for these next-best-action recommendations then they are used to make predictions regarding outcomes and to thereby set the optimal defaults for the current customer.
All of the data and outcomes are recorded for alerting and subsequent monitoring, to ensure that our recommendations are not biased and can be explained on request.
This architecture also supports closed-loop learning, by recording all data and outcomes for each action recommendation to enable the dynamic retraining of machine learning models, such as described in our work on contextual bandits and continuous intelligence.
In following posts we will unpack various elements in this architecture, to outline what the important capabilities are in each area, what integrations are necessary with external tools, and how this architecture may be incrementally built out without requiring the wholesale replacement of current data infrastructure.
One thing is clear - the world is becoming increasingly digital and automated decisioning is key to making this happen efficiently and safely. Ensuring that we design the right guiderails and protections into these systems by design is vital.