
MLOps is a rapidly growing field aimed at standardising and streamlining the lifecycle of ML models, from development and deployment through to ongoing maintenance. In this post we discuss some key considerations when selecting the right set of MLOps tools for an organisation.
What is MLOps?
The basic description of the ML lifecycle tends to follow a familiar pattern. Typically, a business goal is defined, the relevant data collected and cleaned, and an ML model is built and deployed. These steps are then iterated as required to achieve the business goal. However, the experience of real-world organisations has shown that the process of developing, deploying, and continuously improving ML models is much more complex [1], and often results in onerous ongoing maintenance costs [2]. The reasons for these undesirable outcomes include:
- The multiple teams required to deliver enterprise-scale ML projects are often from different disciplines (data scientists, software engineers, model risk auditors). These teams typically speak different languages, and failures can occur at the interfaces between them.
- The data used to fuel the ML models is constantly changing, as are the business requirements that are driving the project. Failures can occur between different phases of a project.
- The infrastructure required to support the ML model, from initial development through to deployment and ongoing maintenance, is large and complex (as in the figure below from [2]). Failures can occur between the various components of this infrastructure.
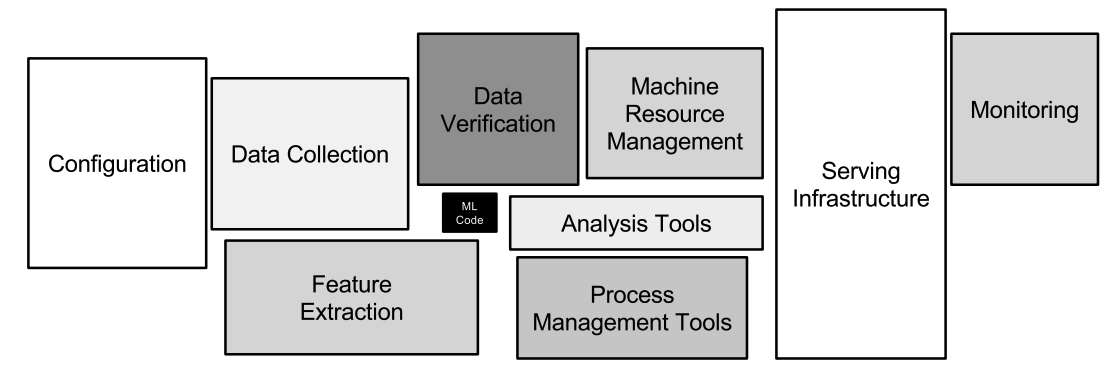
In order to address these issues, various processes and tools have been developed, and are referred to collectively as MLOps. The goal of MLOps is to standardise and streamline the ML lifecycle [3] according to sound engineering principles [4]. Informally, it is the difference between solo data scientists working on small datasets on their local machines, and data science teams deploying production models that are reproducible, auditable, and maintainable by others.
Considerations for choosing MLOps tools
As is often the case in nascent fields, a huge variety of tools have been developed and are now available to help manage the MLOps process. The challenge in this scenario is then to ensure that the relevant factors are considered when choosing the tool set. In this post, we explore various factors worth considering in the decision process and outline a resultant set that suits the needs of Ambiata.
Candidate tool set
There are many more tools than can be reasonably covered, so for purposes of this discussion, we consider the following, non-exhaustive list of options:
- Weights & Biases
- Kubeflow
- MLflow
- Polyaxon
- Comet
- DVC
- Pachyderm
- Neptune
- Replicate
- Optuna
- Ray-Tune
- H2O
- DataRobot
- Domino
- Seldon
- Cortex
- Hydrosphere
Coverage of MLOps tasks
There are many MLOps tasks that must be addressed, and the various tools have taken different approaches that result in long lists of associated features. A helpful initial step to organise these often overwhelming lists of features is to group the tools together into the following four categories:
- Data and Pipeline Versioning: Version control for datasets, features and their transformations
- Model and Experiment Versioning: Tracking candidate model architectures and the performance of model training runs
- Hyperparameter Tuning: Systematic optimisation of hyperparameter values for a given model
- Model Deployment and Monitoring: Managing which model is deployed in production and tracking its ongoing performance
By defining these tasks as the ones that the MLOps tools must address (we will discuss the much wider topics of explainable AI and responsible AI in future posts), we can then roughly match each tool to one or more tasks and identify combinations of tools that cover the full range of tasks. This is illustrated in the table below.
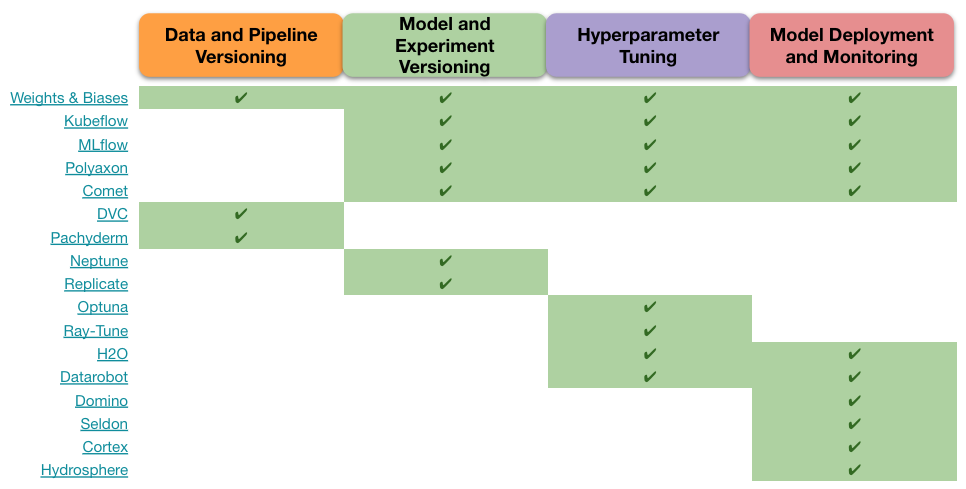
Note that the delineations between tasks are not clear cut, as various tools can address the same task with different levels of depth.
The table shows some tools (e.g. Weights & Biases, Kubeflow) cover a larger scope of tasks, while others (e.g. DVC, H2O) focus on single tasks.
The obvious question that arises from this assessment is whether it is better to choose an all-in-one tool, or piece together multiple tools that are specialised at each task. We need to consider how well an all-in-one tool does each task, or whether we could get the best of all worlds from multiple tools. When piecing together multiple tools, we need to gauge whether there are any gaps in functionality, and areas of functionality where multiple tools may overlap.
Coverage of required libraries
Data scientists use different languages and libraries for developing ML models, and the MLOps tools must be able to support the ones required. Again, we consider a non-exhaustive list of common libraries in the table below.

In the matrix, we can see that for tools that focus on data version control (DVC and Pachyderm), there is no constraint on what libraries can be used. MLflow appears to support more libraries than Kubeflow, while TensorFlow is the most widely supported library. Also, we should note that this candidate set of tools considered here all work with Python.
For data scientists, an obvious consideration is the level of support for Python and/or R. The stack can be greatly simplified if only Python support is needed, but there may be situations that require the use of R.
For the other libraries, there is the question of how wide the scope needs to be. Can we restrict the scope to a small number of libraries and still fulfil the range of business requirements? Will the users be a small team who all use the same libraries, or for a more diverse team with different library requirements?
Level of product support
For a reliable and maintainable stack, it is important to consider the level of product support available for each component tool. The level of product ‘momentum’ can also be an indicator of how much product support will be available in the future. A related question is whether to rely on open-source or commercial software.
In the table and chart below, we consider the number of GitHub stars and employees/contributors (as at December 2020) to be proxies for the level of product support for each MLOps tool.
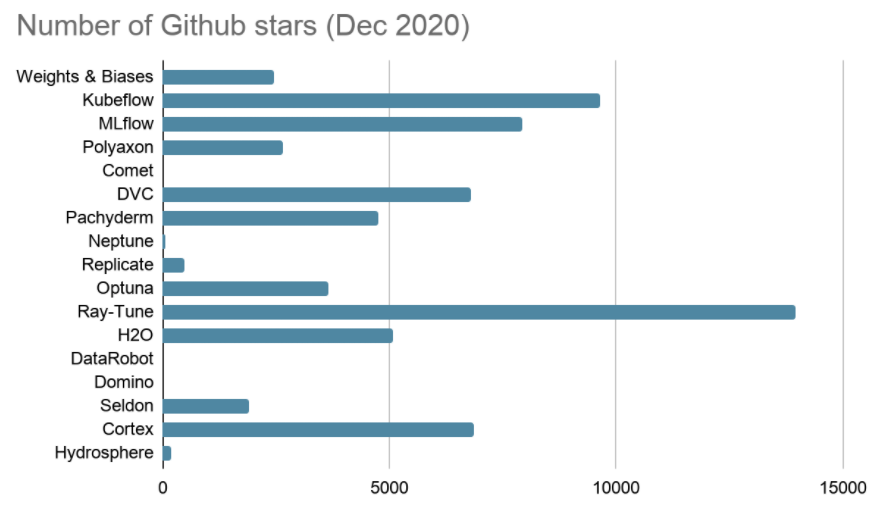
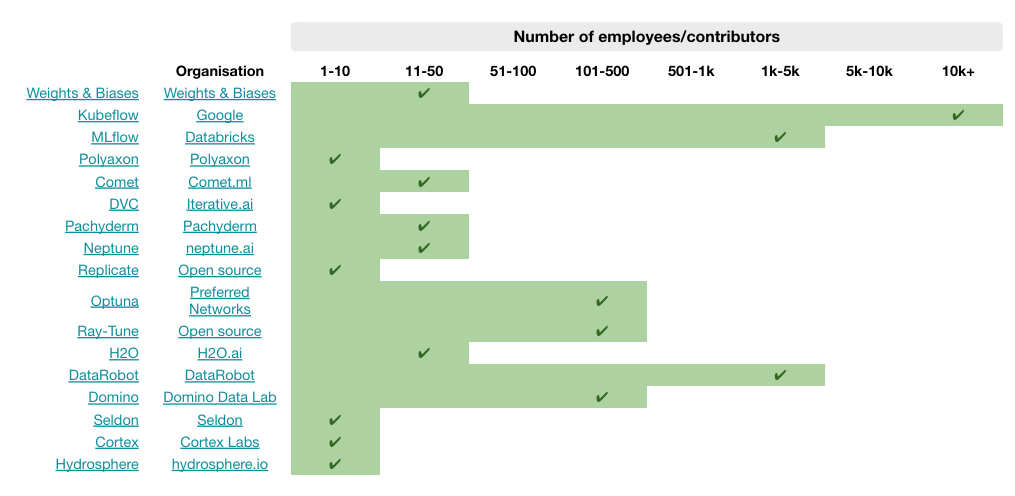
When based on the number of GitHub stars, the hyperparameter tuning tool Ray-Tune has the most support, followed by Kubeflow and MLflow. When based on the number of employees/contributors, Kubeflow (Google) has the strongest support, followed by MLflow (Databricks) and DataRobot (DataRobot).
The tradeoff to consider here is that commercial tools with reliable product support tends to come with additional costs. Also, there may be more development effort required to migrate onto (or away from) highly supported tools. Furthermore, there may be a mismatch between the level expertise that the product is designed for, and that of the actual users.
CLI versus GUI
A more subjective point to consider is whether or not a tool is well-matched to the expertise and working style of the user. Given the diverse skillsets of different data scientists, one way this issue emerges is whether they prefer command-line interface tools (and notebooks) or more graphical user interfaces.
While many MLOps tools offer both types of interfaces, the way they are designed to be used typically highlights one interface type over the other. The table below is a rough and subjective categorisation of whether the usage of each tool is designed primarily around CLI or GUI.
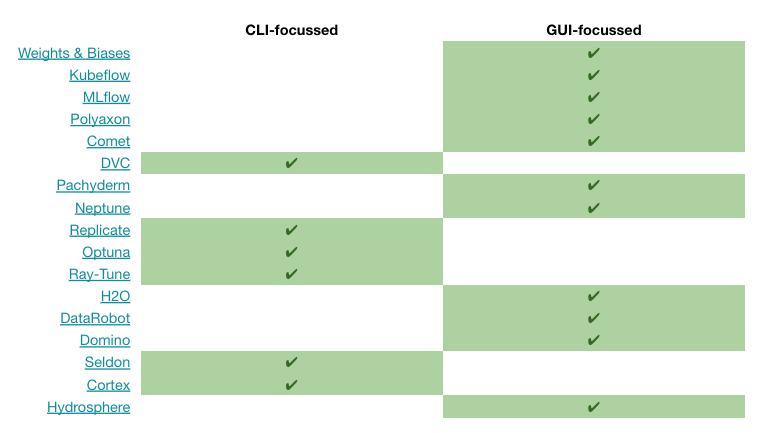
Most larger tools (e.g. MLflow) have a GUI focus, with additional CLI support. Other smaller tools (e.g. DVC) are more heavily CLI-focussed.
Cloud-agnosticism
A basic but important question is whether the MLOps tools are intended to be cloud-agnostic, or if there is only a single cloud provider to consider (i.e. AWS, GCP, Azure).
If only one cloud provider ever needs to be considered, then a possible solution is to simply use the tools of the relevant provider (i.e. AWS SageMaker, Google Cloud AI Platform, or Azure Machine Learning). These tools may integrate more easily with your existing overall architecture, whilst still offering most, if not all, of the MLOps features that your organisation needs.
However, if multiple cloud providers need to be considered, then the MLOps tools will obviously need to be cloud-agnostic. The candidate tools explored in this post are all cloud-agnostic and are therefore distinct only from the cloud provided tools, and not each other.
MLOps tools for Ambiata’s needs
At Ambiata, we used the preceding considerations to outline a promising set of tools that meets our requirements. Specifically, our tools must be cloud-agnostic. They should not lock us into a single platform and should ideally be open-source. They should support a wide range of libraries and be backed by significant product support/momentum. While they should focus on Python, they should also support R for some specific tasks. They should also allow the development of custom models. Lastly, while the CLI vs GUI issue comes down to user preference, the git-based workflows we already have are better suited to CLI tools.
Given these requirements, we can use the following tools to cover the four MLOps tasks:
- Data and Pipeline Versioning: DVC is a standout choice as it is very lightweight, open-source, and designed explicitly to work with git, which is already a core part of our existing workflows. Also, there is minimal development effort required to get benefits from DVC.
- Model and Experiment Versioning: MLflow is a balanced choice because it manages to support a wide range of libraries, while still requiring relatively little development effort to use (it is a single Python package). As an open-source project, it has a good amount of product support/momentum behind it.
- Hyperparameter Tuning: Optuna is an easy-to-use and well-documented tool for hyperparameter tuning. It can work with MLflow, but deeper integration in the future would be useful.
- Model Deployment and Monitoring: Seldon Deploy is useful because it supports of a wide range of libraries, and allows us to deploy custom models.
Closing thoughts
At the start of this post, we discussed some of the issues that arise in practical ML model lifecycles which have recently led to the rapid rise of MLOps as a field. The purpose of the remainder was to discuss some of the key considerations for organisations looking to choose MLOps tools for their own stack. As the requirements of each organisation will differ, there is no single best combination of tools. However, we can use the preceding considerations to select a set that best matches the given organisational needs.