
Real-time personalized recommendations in enterprises with contextual bandits. Keep your automated recommendations relevant in a post COVID-19 world. Using Hybrid Cloud and AI to activate your data at speed.
Introduction
In this post, we discuss the learnings from a Proof of Concept (PoC) undertaken by Ambiata and IBM to determine the benefits of running Ambiata’s continuous intelligence system, Atmosphere, on IBM OpenPOWER systems (AC922).
First, some context. Real-time decision making using all the data at hand has been a key success factor for companies like Google, Amazon, Netflix, Spotify, etc. For these internet giants and born-in-the-cloud companies gaining insights from data using Artificial Intelligence (AI) is second nature. However, for many others, including large enterprises and governments, unlocking value from silos of data has been a challenge traditionally. As these organisations advance through their digital journeys, they are making progress in leveraging more of their data. The advent of Cloud, the fruition of AI, modern tooling and platforms are key to making this possible.
Another reality faced by many of these organisations is the need to maintain multiple generations of systems and applications with diverse architectures. As nirvana-like Public Cloud is, it is not feasible, cost effective or advisable for these organisations to be 100% on Public Cloud. It is often necessary to keep the data where it is – why move big data against gravity to the Public Cloud just to get some insights from it? – particularly, if the operational source of that data is not on Public Cloud. Plus, there is growing awareness and pressure to keep data on-prem or in-situ for sovereignty, security and even cost reasons. And new tooling - with Kubernetes and Hybrid Cloud - can merge the benefits of Public Cloud with on-prem compute to give the best of both worlds. Additionally, GPUs and accelerators now make is possible to crunch data in-situ or on the fly to extract the essence (insights) of it in real-time.
Ambiata and Atmosphere
This brings us to how this PoC came about. Ambiata’s Atmosphere software is a real-time decision-making engine that learns continuously from historic and online data to help an agent/system make optimal decisions based on contextual information. When deployed on Public Clouds, this requires all the necessary historic data to be moved to the Public Cloud. For many large enterprise and government clients that have much of their historic and operational data on-prem and in many distributed systems, this is a challenge and costly. The AI in Atmosphere is based on a combination of deep neural networks which benefit greatly from GPUs, and complex statistical models of uncertainty which are run on the CPU.
IBM Power Systems run operational workloads in many Enterprises and government and in recent times with OpenPOWER based systems (AC922), Power systems are also able to run modern AI workloads at scale. Given the in situ extraction need and IBM’s presence, Ambiata and IBM embarked on this PoC to explore the benefits of running Atmosphere in a hybrid deployment model – where the real-time data extraction from enterprise data would take place on-prem and the online element could run on either Public Cloud or on-prem.
What problems are we attempting to solve?
Many of these large enterprises and governments now understand the importance of AI to provide personalized services. Reinforcement Learning (RL) based Contextual Bandits systems such as Atmosphere can be the personalized recommendation engine within the organizations’ AI software suite. Examples of where these systems are used include personalizing the user experience of websites and applications, personalized offers, routing of customer complaints, optimizing sales funnels, news article recommendations, and other similar systems. Many consumer platform systems are personalized this way – a well-known example is the Netflix app, where almost every aspect is personalized on the fly, taking into account the user’s viewing history and preferences to present the most engaging content to them in the most engaging way.
The advantage of these systems is that they adapt dynamically to changes in both the environment – by continuous learning and exploring to determine the best options – and in the application domain itself – allowing new options to be dynamically included without having to start from scratch.
For instance, during the COVID pandemic, the Australian government swiftly announced tax/relief measures, but the applicable conditions and details were refined over time. Citizens could have benefited a great deal if the Australian Tax Office (ATO) website could display a personalized list of applicable tax bills for each citizen when they visit the ATO website. On a normal day, ATO could have leveraged the massive amounts of historical information they have gathered over the years for this purpose. However, during these unprecedented times recommendations solely based on historical information are inadequate because circumstances have changed a great deal since the pandemic started. At times like these, to provide continuous intelligence services enterprises must use state-of-the-art ML (i.e, contextual bandits, deep neural networks) for efficient continuous learning from both online and internally held data. At the same time, enterprises must invest in enterprise-level hardware to deploy these ML models.
Even simple systems, such as those that suggest which payment options may be ideal for a product or service for a given customer, benefit from these approaches. Traditional machine learning models are stuck in the era in which their data were collected. In the turbulent times we now live, it is important to be able to dynamically respond to changes in people’s preferences and ability to pay, and to do this at scale in an automated way.
Contextual Bandits, Reinforcement Learning and Thompson Sampling
The learning setup in the PoC was a recommendation engine based on contextual bandits and deep neural networks. Contextual bandits, a versatile set of reinforcement learning algorithms, can leverage by design both historical and online data to recommend timely and relevant actions. Contextual bandits do this by making use of the user feedback for each recommendation and continuously updates the model to find optimal recommendations. In this PoC, the recommendation engine consists of two major components: (1) a dense neural network that captures the historical recommendations and rewards; and (2) an online learning model based on a process known Thompson Sampling. There are periodic updates to the neural network to learn the users’ context, recommendation and the reward obtained. The Thompson sampling model is updated with each feedback and acquires new information to reduce the uncertainly in the entire learning process. With this learner setup, we can both exploit the historical information using the dense neural network and explore new avenues using the Thompson sampling module. As a result, the learner can quickly learn the most relevant recommendation in different contexts.
The PoC set-up
In this PoC we compared the performance of the above learner setup using simulated data on an IBM POWER AC922 against a baseline (AWS P3.2xlarge). The IBM AC922 was set up with 32 cores, 4 Tesla v100 GPUs with 16GB (only 1 GPU enabled for the PoC performance comparisons) and 512 GB RAM (only 61GB made available for performance comparisons). The AWS instance had 8 vCPUs, 1 Tesla V100 with 16 GB and 61 GiB RAM. The objective of this PoC was to test the viability of running the real-time decisioning engine (core of Atmosphere) on POWER and to understand the advantages presented by the high-bandwidth link between the GPU and CPU in the context of the mixed CPU/GPU workload of the contextual bandit system.
As described above, many uses of AI today require large neural networks. Within Atmosphere, the neural network architecture is configurable, and applications such as real-time recommendations based on text or voice can require such models. To explore the ability of the POWER architecture to support such large models, for the POC we configured TensorFlow with Large Model Support (LMS) on the AC922, and benchmarked its performance against the equivalent AWS system for different sizes of Dense Layer neural networks configured within Atmosphere.
LMS on POWER
IBM OpenPOWER based servers were designed for the era of big data and AI workloads together with an ecosystem of 350+ partners, to bring about an #open architecture and ecosystem, similar to that of ARM. To overcome the limits of Moore’s Law reaching its end of life, the OpenPOWER architecture allowed for the coupling of accelerators (GPUs and ASICs) via high speed interconnects (NVLink and CAPI) in addition to PCI-e. NVIDIA’s NVLink – typically used for the interconnect of multiple GPUs – is also used as the interconnect between the CPU and GPU on the AC922. The AC922 is the building block of the word’s largest supercomputer at Oak Ridge National Laboratory
Now onto LMS. First, let’s discuss the need for Large Model Support when training Deep Neural Networks. The amount and size of data to process are always growing. To model these complex interactions and patterns neural networks keep getting deeper and wider. It is not possible to load these large models along with the associated training data into the limited memory of a GPU. LMS allows us to overcome this limitation with tensor swapping - active tensors of a model to be in the GPU memory and maintains a set of inactive tensors eligible for eviction. The inactive tensors are paged out to the main memory of the system, which is typically much larger than GPU memory (512GB vs 16GB in the AC922). With a high speed (170GB/s) NVLink 2.0 link between the GPU and CPU, this tensor swapping can be achieved with minimal overhead. This allows for the training of higher resolution data, deeper models and larger batch sizes.
Learnings
In this PoC we experimented with two scenarios: (1) In the first scenario we trained the learner without Large Model support; and (2) in the second scenario we enabled Large Model Support with memory defragmentation enabled. We executed identical jobs on both the OpenPOWER AC922 system and the AWS P3.2xlarge. As a learning task we simulated a mixed categorical and numeric online personalization task with 8 possible actions, 80 features, and a 15% acceptance rate. Our primary performance measure is the execution time (seconds) per round of 1000 online observations, including a retraining of the underlying neural network architecture (smaller is better). In the chart below we show this execution time as a function of the size of dense layers in our deep neural network, illustrating the performance behaviour of the contextual bandit system expected with increasingly complex neural architectures.
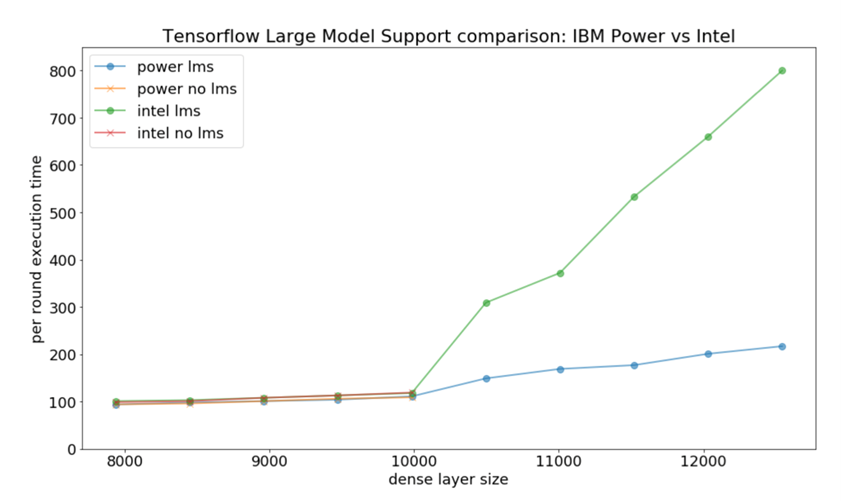
The 4 lines on the chart show that for smaller network sizes, the AWS intel system and the POWER system show relatively similar performance characteristics. Without Large Model Support enabled both systems fail to complete a round for layer sizes > 10000. With LMS enabled, the POWER architecture dramatically outperforms the Intel architecture due to the high speed interconnect with main memory enabling efficient swapping of memory with the GPU.
Conclusion
This PoC demonstrated the suitability of the POWER architecture for AI workloads that require a mix of both GPU and CPU compute. In particular, it demonstrated that with Large Model Support enabled, the POWER architecture can be used to efficiently support large models that exceed the raw capacity of the GPU.
IBM and Ambiata are continuing to explore the capabilities of the POWER architecture for Reinforcement Learning workloads such as the continuous intelligence algorithm in Atmosphere. In particular, we are examining how to use LMS to efficiently pack more personalization engines onto a single GPU, and to move compute between on-prem and in-cloud instances when there is high contention for resources.
Contextual bandits are a powerful and modern way to activate your enterprise data for your customers – you don’t need to wait for the data lakes to be created – you don’t need to move all your data to the Cloud - just start unlocking the value of data in-situ. Combining these advanced AI techniques with IBM’s unique accelerated hardware, presents an exciting opportunity to improve your customer outcomes.
If you want personalisation that adapts to changing circumstances, built on your internal data, then contact one of the authors below.
Authors
Stephen Hardy, CEO, Ambiata
Min Sub Kim, Data Scientist, Ambiata
Nirandika Wanigasekara, Data Scientist, IBM Systems
Wijay Wijayakumaran, Chief Architect - AI, IBM Systems