
Next-best-action systems are often used to optimise business metrics and individual customer outcomes, but could they also become a vehicle for promoting social good? In this post, we explain why organisations can leverage next-best-action systems to promote fairer and more equitable outcomes for their customer base while still maximising profits.
This is a guest post by Tiberio Caetano, Chief Scientist at the Gradient Institute, who are an independent, not-for-profit research institute whose purpose is to progress the research, design, development and adoption of ethical AI systems. Tiberio was also Ambiata’s former Chief Scientist.
Organisations have an incentive to be socially responsible
Today most successful organisations practice some form of “corporate social responsibility”. This means they allocate funds to pursue pro-social objectives in addition to maximising profits through their core business operations. Some examples are charitable giving, active reduction of carbon footprint, participation in fairtrade and community volunteering.
Even though such initiatives may well entail a genuine ethical motivation, companies do have an incentive to implement them as customers are often attracted to brands they perceive as more ethical. By foregoing some revenue in the short-term, the company expects to enhance its brand image so as to drive future sales. In other words, pursuing social good is not necessarily detrimental to the bottom-line, but can constitute a competitive strategy in and of itself. It’s a public relations investment that can pay off.
Although different industries vary greatly in the extent to which and how they make social contributions, the overall trend points towards an increase in both size and forms of participation, in line with growing consumer and societal demands on issues such as climate change and social inequality. Take the example of fossil fuel divestment, which within a decade went from a target of student advocacy on campuses to becoming the fastest growing divestment movement in history1.
What’s next? Which new policies for corporate social responsibility could be effective both from a social and business perspective, but today still lack broad recognition? We may find an unusual suspect in next-best-action systems.
Organisations already use next-best-action to drive profit
Companies are increasingly recognising the potential of combining data, machine learning, experimentation and personalised intervention channels to create automated decision making systems that drive better customer outcomes and improve the bottom-line. These are often called next-best-action2 systems, and are designed to optimise the interactions with customers in order to maximise profits for the organisation.
Who should be notified about a new product? Is it time to give that customer a discount? Through which channel to advise this bill is overdue? Such decisions used to be made through pre-programmed business rules encoding untested assumptions. Today they are based on approaches involving machine learning and experimentation, such as contextual bandits or other reinforcement learning techniques. These methods produce “algorithmic policies” that make decisions for which there is past evidence of improvement on explicitly stated objectives. In other words, the policies favour decisions that were previously “successful” in a similar context and for similar customers, for a given precise definition of success. Decisions are optimised to drive the stated objective (often conversion rates or other proxies for revenue or profit).
And it works. These approaches can be validated rigorously through randomised controlled trials - the gold standard for inferring the effectiveness of an intervention, be it a new drug, a new vaccine or a new algorithmic decisioning policy. Such trials reveal that policies directly optimised to drive a certain metric tend to yield superior outcomes on that metric.
This scenario prompts interesting questions. If such systems are capable of optimising aggregate customer outcomes, could they also promote social equity across the customer base? And could that pay off as a business investment?
Why companies can exercise social responsibility through next-best-action
Before asking if a next-best-action system can undergo an ethical uplift, we must ask whether the purpose for its existence is ethical and compliant with the law. That can be a fraught question, but it’s hard to see how a company can be doing the right thing by improving the ethics of how it deploys an algorithmic decision system without first establishing whether the system should exist. Just doing less moral damage isn’t good enough if the best is to have no system at all.
Assuming the purpose for creating a next-best-action system is ethical, there are four facts that together help explain why it’s possible to adapt it so as to contribute to social goals.
First, profit is driven by predictive accuracy. The key factor influencing the ability of a next-best-action system to deliver profit uplift is how accurately its deployed model can predict the response of individual customers to specific interventions. Say a certain group is eligible for two offers, one more profitable than the other for that group. A model that’s 70% accurate at determining what the most profitable offer is will pick it more often than a model that is only 60% accurate - thereby yielding higher profit.
Second, if two models have the same accuracy across the customer base, it doesn’t necessarily mean they are equally accurate for different people or groups of people. Different models can differ in the predictions they make for individual customers, and yet have essentially the same aggregate error rate.
Third, how the accuracy of a model is distributed across the customer base has moral significance. For instance, if a system proves to be substantially more accurate for customers who are affluent and privileged than for customers coming from a historically disadvantaged minority, the system will be susceptible to making more errors within the group that is already less well-off, thus potentially reinforcing existing societal inequalities.
So far there are no big surprises; these facts are reasonably intuitive. The following is perhaps less intuitive as it has to do with the multitude of ways a powerful machine learning system driven by rich data can achieve a stated goal
- In real-world scenarios, there is often more than a single model that maximises total accuracy across the customer base. There is usually a range of models with essentially the same maximum total accuracy which instead differ in how that accuracy is distributed across customers.
This is key, and below we elaborate on it. Although the range can still vary substantially depending on context, in practice there is some room for choosing which profit-maximising model to pick3. And, because the choice has moral significance, there is an opportunity to choose the model that maximises a predefined social objective among those that maximise profit. And this is just what a viable policy for corporate social responsibility looks like.
The steps required
Prioritising social objectives
The first step is to decide which social objectives will be accounted for in the next-best-action system, and how they can be encoded in terms of the data available to the system.
Prioritising a set of social objectives means deprioritising others, so the first thing to notice is that not everyone wins. This is no different than for other social policies that companies already engage in - if a business donates to charity, the bill is effectively being subsidised by the customer base.
What’s different in the case of policies driven by next-best-action systems is that the beneficiaries always belong to the customer base. For instance, a company may want to use this approach to selectively improve customer service for a socially disadvantaged group of customers, such as First Nations peoples, immigrants, the elderly, or low-income households.
In order to do that ethically, the company must adopt an ethical stance about which groups of customers will be the target of the social policy, and be prepared to justify its position.
Encoding social objectives
Since a next-best-action system can only see the data available to it, it is crucial that information identifying the target groups is identifiable from the data. For instance, to create a social policy targeting the elderly, age group information or a reasonable proxy thereof must be available.
In addition, a precise definition of what constitutes a “benefit” must be encoded in the system, and the accuracy of the system should be measured with respect to actual benefits realised. The expected benefit of allocating a certain intervention depends on the nature of the outcome, the value of the outcome, and the chances the intervention has to drive the outcome. Say for example our interventions consist of several types of discount offers, and we want to apply an algorithmic policy that not only maximises profit but also allocates more substantial discounts for low-income groups. In this case, a possible choice for defining “benefit” afforded to a customer under a given offer is the expected savings obtained by the customer.
Once we have encoded which groups will be the target of the social algorithmic policy, as well as what constitutes a benefit, we are left with the task of designing a next-best-action system that realises the benefit for the chosen group.
Designing a next-best-action system that realises the social objectives
The figure below expands on point number 4 above. It shows qualitatively a typical empirical relationship between total accuracy and the magnitude of some form of “social contribution” made, for different model choices (each point in the curve corresponds to a different choice of predictive model), assuming the models are trained from the same fixed dataset. An example of social contribution would be a relative increase in the predictive accuracy for a protected minority when compared to the rest of the population, which translates to increased benefits for that group. There are a couple of noteworthy aspects in this diagram.
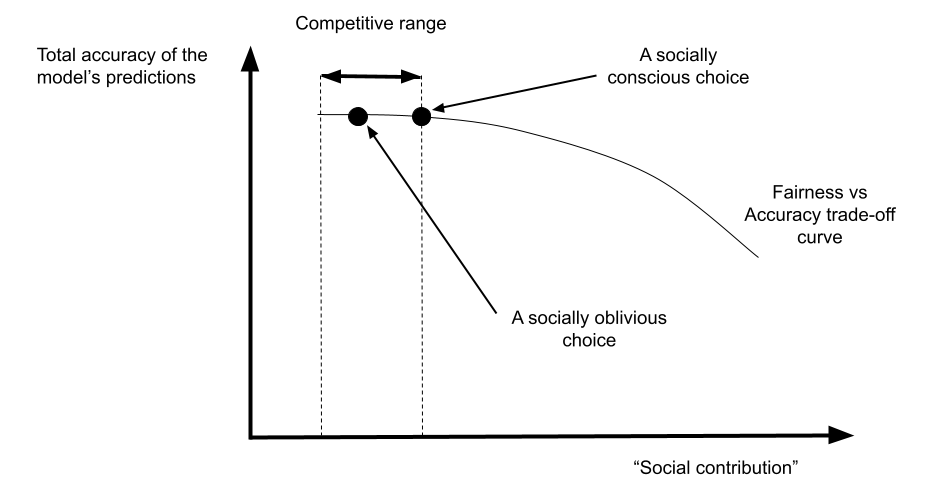
First, note that in general there is a trade-off between total accuracy and the amount of social contribution. The research literature documents this trade-off for a variety of ways of quantifying social contribution, often framed as “fairness”4.
Second, the curve starts somewhat flat: note the “competitive range”. This refers to the set of models that deliver basically the same level of total accuracy (say within a fraction of a percentage point in relative terms, or within a noise region) and yet have materially different levels of the social contribution score. The precise delineation of this range is somewhat arbitrary, but it’s both conceptually and practically useful. Conceptually because it allows for simple communication with stakeholders, and practically because in order to design a real system we need to impose a maximum loss of accuracy we are willing to take - even if it’s a negligible one at the noise level. A “socially conscious choice” within the competitive range (as opposed to a socially oblivious choice) would be one that proactively maximises the social contribution score in that range.
(If we depart from the competitive range, we will be able to further increase the social contribution, but noticeable losses of accuracy will translate into short-term profit loss. This may still be a reasonable business decision, such as when there is compelling evidence the social policy will lead to long-term business growth).
How wide is the competitive range? It depends. It can vary significantly across data sets, the class of machine learning models used and heterogeneity of the customer base. Only an empirical assessment on a case-by-case basis can provide a good answer. Relative improvements of tens of percentage points on a social criterion are not uncommon for a negligible loss in accuracy3.
In practice, how do we find the most “socially beneficial” model within the competitive range? We can adapt the machine learning algorithm to trade-off a gain of accuracy in the target group against a loss of accuracy in the remaining population, while enforcing at most a negligible loss in total accuracy3. The power of this intervention grows with the availability of data per customer, the number of customers and the number of parameters of the model. If in addition to that we can collect more data on the target group, the prospects improve even further as the curve itself will shift towards better trade-offs.
Relationship with algorithmic bias5
It’s by now widely recognised that algorithms, just like people, can make biased decisions. This partly comes from the fact that the world is biased and data used to train algorithms is a projection of the world. But also comes from poor choices in collecting and curating the data as well as designing the decision-making system6. Finally, there are some fundamental trade-offs that imply that reducing certain kinds of biases will always increase others, so we can never be free of some form of bias4.
How does our discussion about the possibilities of using algorithmic decisioning to improve social outcomes relate to issues of algorithmic bias?
At a high level, algorithmic bias can be seen as a force towards the amplification of existing structural injustices in our society. For automated decisions in recruiting, naively designed machine learning algorithms will tend to recommend high-paying jobs for people who look like others who in the past were over-represented in high-paying jobs (e.g. men). For automated decisions in the criminal justice system, they will tend to assign higher risk for people who look like others who in the past were over-represented in the criminal justice system (e.g. ethnic minorities). This generates a positive feedback loop that further entrenches social injustice.
Instead, what we have discussed in this post can be thought of as a force in the opposite direction: algorithmic fairness7. It partly arises from a recognition of the need to fight algorithmic bias - but only partly. Even if care is taken with both data and system design so as not to perpetuate or amplify historical biases, there is still the question of which criterion and method a company will use to distribute benefits and costs over and above that baseline. Finding a criterion is an ethical and political question, just like many others in public policy and governance. Finding a method is a technical question, in this case addressable through suitable data collection and design of a machine learning algorithm.
Summary
The central claim of this post is that next-best-action systems can be a force for social good.
Most such systems are currently optimised to maximise total profit, without additional constraints on how that profit ought to be distributed across the customer base.
We have argued that mass personalisation through data and machine learning enables the creation of a range of models that maximise profit, and thus a company can pick among them the one it deems to be most socially beneficial without harming the bottom-line.
Learn more
Ambiata is proud to partner with the Gradient Institute, who are world-leading researchers and practitioners on ethical AI systems, which allows us to build ethical foundations into our engagements. If you would like to explore AI ethics technology safeguards in your next-best-action system, please contact us at info@ambiata.com or on the web form on our main page.
Fossil fuel divestment: a brief history. https://www.theguardian.com/environment/2014/oct/08/fossil-fuel-divestment-a-brief-history ↩︎
An architecture for enabling next-best-actions for your customers. https://ambiata.com/blog/2021-01-21-architecture-next-best-actions/ ↩︎
Characterizing Fairness Over the Set of Good Models Under Selective Labels. https://arxiv.org/abs/2101.00352 ↩︎ ↩︎ ↩︎
Inherent Trade-Offs in the Fair Determination of Risk Scores. https://arxiv.org/abs/1609.05807 ↩︎ ↩︎
How to detect algorithmic bias in production. https://ambiata.com/blog/2021-03-09-how-to-detect-algorithmic-bias-in-production/ ↩︎
Artificial intelligence can deepen social inequality. Here are 5 ways to help prevent this. https://theconversation.com/artificial-intelligence-can-deepen-social-inequality-here-are-5-ways-to-help-prevent-this-152226 ↩︎
Bias Preservation in Machine Learning: The Legality of Fairness Metrics Under EU Non-Discrimination Law. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3792772 ↩︎