
A system for next-best-actions needs to resolve several challenges related to data access. In this post, we outline a two layer API approach that allows the joining of online and offline data, and also allows the routing of traffic to different recommendation methods.
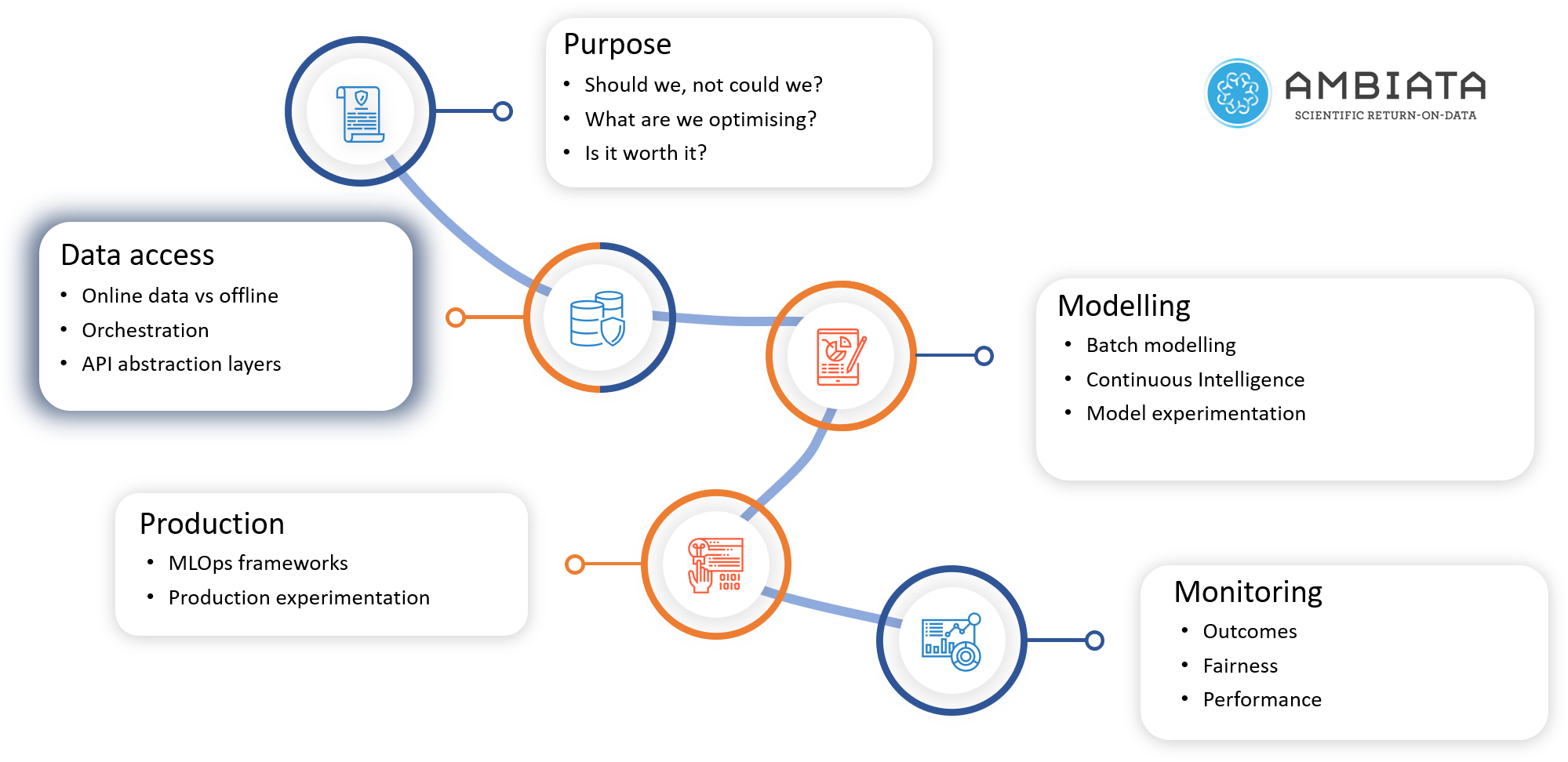
In the first part of our series on building out the architecture for next-best-action systems, we presented the five key areas that required solving (in the figure below), before then delving deeper into step one, where we looked at the purpose of the use case and asked questions such as “should we, not could we?”, and “is personalisation worthwhile for this use case?”.
In this post, we build out the data access components of the architecture, outlining the requirements, the major challenges presented, and providing a summary of our approach which abstracts the major components of the system through the use of APIs. In the figure, we will be covering step 2.
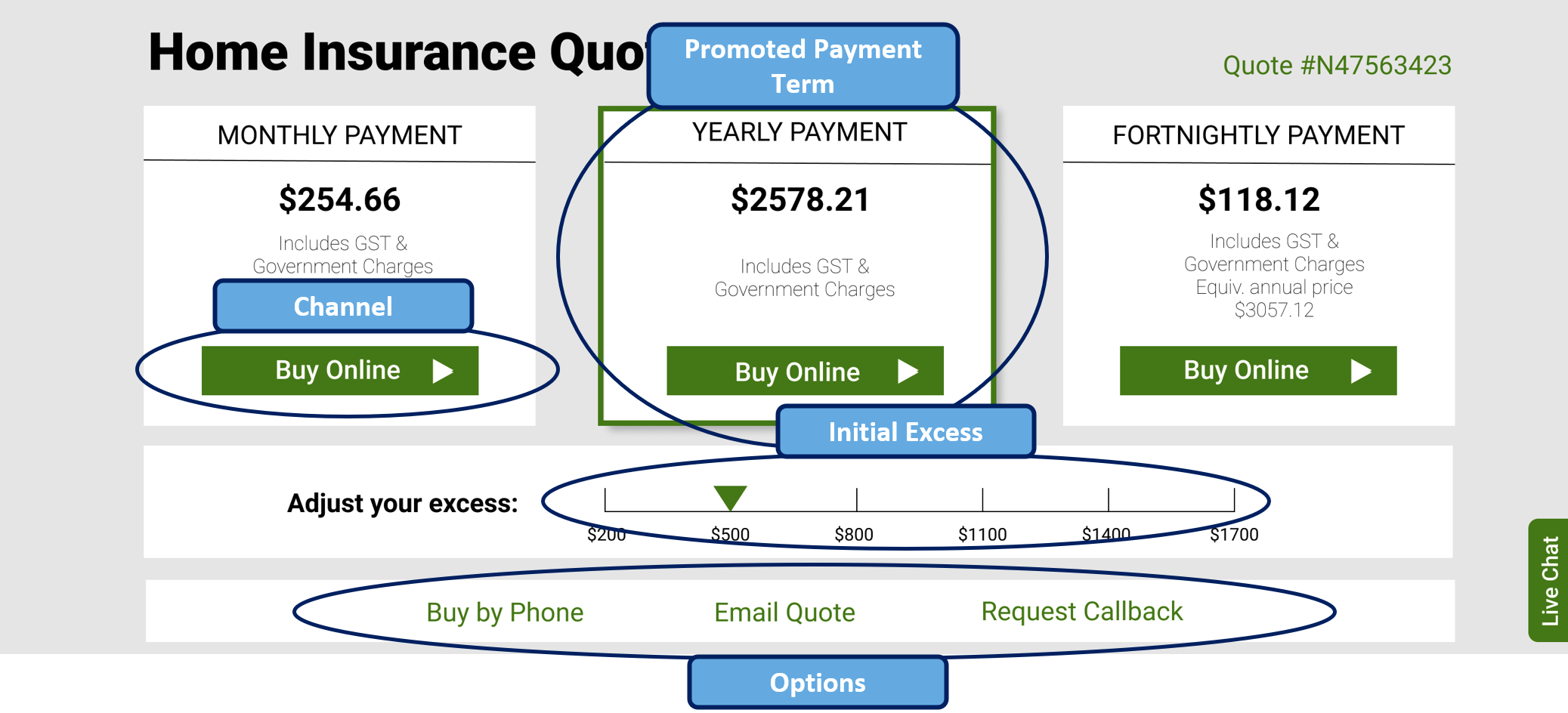
Personalising a quote funnel
Our previous post used the scenario where a customer interacts with your organisation through a digital channel (eg. website, mobile app) and asked the question - when the interaction flow has multiple options, which option should be selected for this customer?
A next-best-action system is one that solves this problem using a design pattern that takes an online context from the digital channel, supplements it with internal data, and chooses between sets of options using machine learning algorithms, with the goal to try to have the customer reach a desired outcome.
The high level flow of the interactions with the system is then:
- A digital service (eg. a web app, mobile app, web form) collects the online context & requests a next-best-action from the system
- The system takes the online context, joins it with the offline context and runs the combined context through an ML algorithm, before returning the best option to perform
- Digital service presents the option to the customer & reports the outcome to the system
- The system records logs of the contexts, actions and outcomes.
We will continue our example of quote funnel personalisation, where a customer is interacting with a web form to retrieve an insurance quote, and the system is aiming to choose the default settings for payment term, excess and purchase option that is used in the quote to optimise the conversion rate.
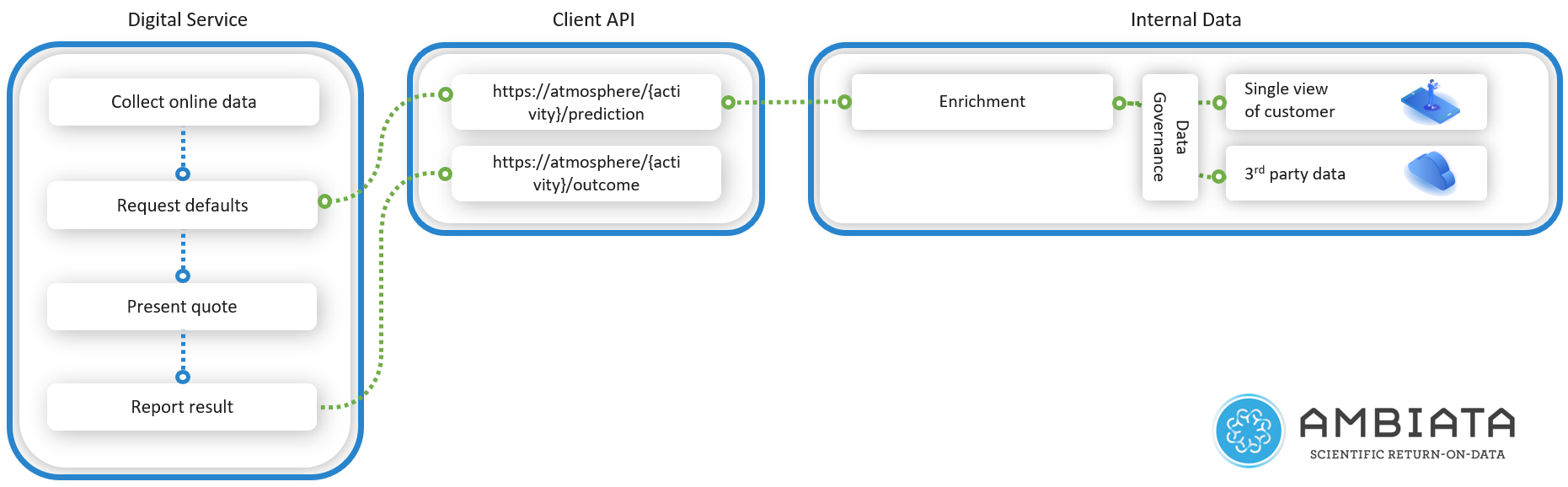
The online and offline contexts
The first challenge the system needs to solve is being able to accept online context data and enrich it with the offline context. By combining the two, a much more complete view of the customer is provided to the recommender which then enables better decision making.
Online context
In our insurance quote example, the online context collected by the web form includes the customer demographics, details of the assets to be insured, as well as some details about their insurance history. In other domains, such as ecommerce, the online context might simply be the basket of items to be purchased.
As the online context is collected from the immediately preceding customer interactions, the data reflects the most up-to-date information. However, this data will typically be limited to the immediate interaction and will not provide a comprehensive view covering any historical interactions and other information previously collected by the organisation.
Offline context
The offline context is the internal data that the organisation typically stores in a Data Warehouse (DWH) or Customer Data Platform (CDP), or any other such feature store. The features that have been engineered will obviously vary depending on the sector and organisation, but will usually include the history of the customer with the organisation and their offering, and potentially make use of third party data.
In our insurance example, the offline context would include further details on additional products held by the customer, payment history, claim history, or even a view of their household, where family members may also be customers.
Joining the contexts
In digital channels, there are three separate scenarios when identifying a customer. The prospective customer may be:
- Logged in
- Not logged in but has a cookie (or other transient id) available
- Is completely anonymous
In the case of scenario 1 and 2, the customer id or cookie id could be used to join the contexts. The quality of the offline enrichments will depend on the sophistication of the feature store implementation, and could vary from simple historical counts (eg. years since becoming a customer), through to rich embeddings taken from unstructured data (representations of previous support ticket text).
In the interaction flow with a customer, the digital service collects the online context and passes it to the next-best-action system via an API. This is the first API abstraction layer and is designed to allow this enrichment step to be done before the recommendation.
Regardless of the exact enrichments being done, this process of joining the contexts is within the interaction flow with a customer, and therefore it must not degrade the customer experience. Specifically, the latency requirements of the process represents the next challenge.
Before moving on, we can see where we are in building out data access in the next-best-action architecture.
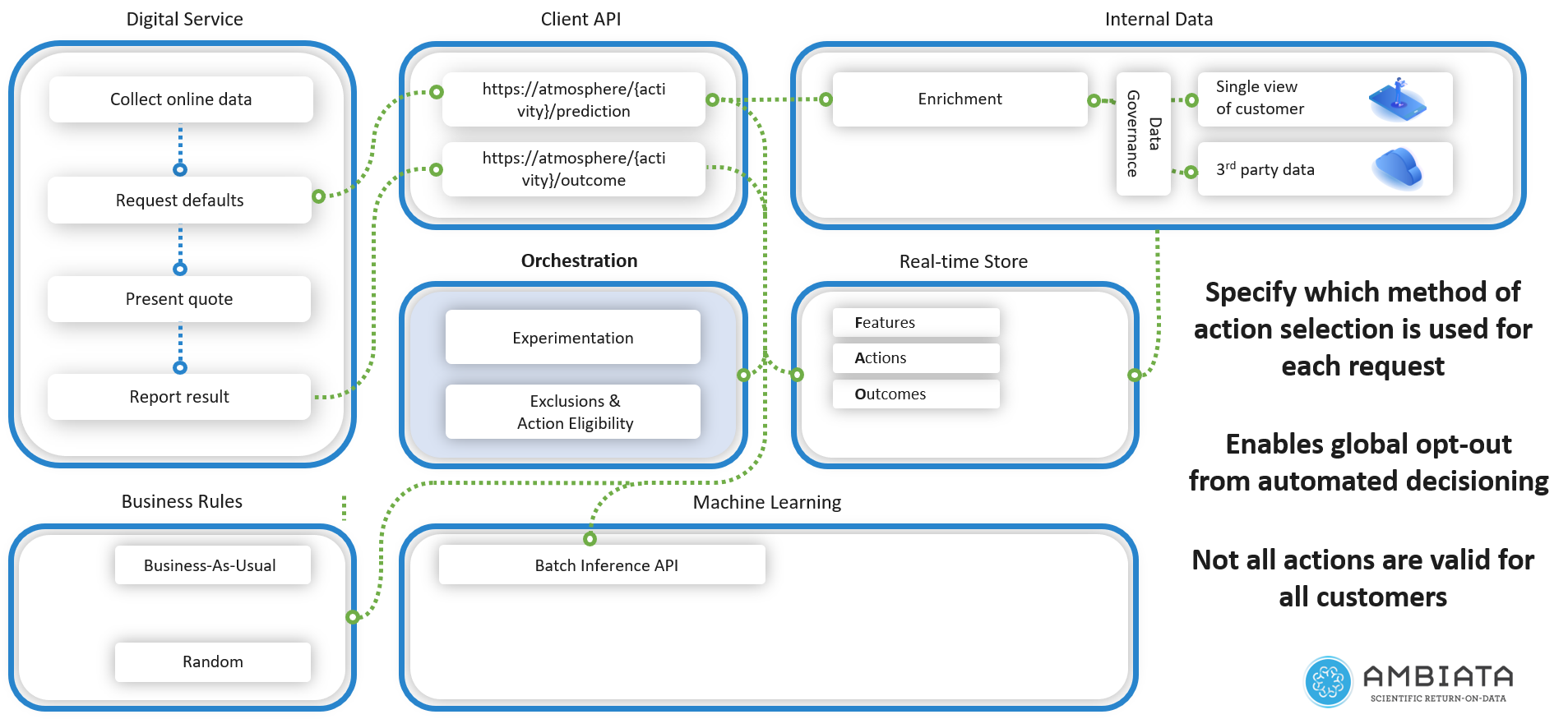
Real-time Store
The requirement for low latency access to the offline context data is solved by introducing the next component in our data access architecture, the real-time store. This consists of one or more databases that provide storage capability and performant queries, which also scales to cater for large data volumes.
Features
Typically, the offline context cannot be provided by internal client data systems within the latency bounds, so the features required are loaded into the real-time store. This approach has the benefit of taking processing workload off the internal client system, but also has drawbacks, such as duplicating effort and increased storage requirements.
Context, Actions, Outcomes
In addition to storing features, the realtime store also records the logs of the contexts, actions and outcomes that are produced. These logs are used for three purposes:
- Auditability - in many sectors, there are regulations requiring the auditability of automated decisioning systems. This also relates to the Australian AI Ethics principles concerning Transparency and Explainability, and also Contestability, which means that people must be able to challenge the decisions made by AI.
- Measurement - evaluation of the performance of the recommended actions and ensuring that the system is not causing unintended ill-effects is only possible if comprehensive logs are available for analysis.
- Collection of training data - the captured data can be used for the training of new or updated ML models.
These topics related to measurement will be further explored in a later post in this series.
Machine Learning and Business Rules
At this point, we have joined the online and offline contexts, and we have a real-time store where we can retrieve offline features and also log each step of the process. We now want to get our recommended next-best-action by running the combined context either through a machine learning model or through business rules.
Machine Learning
In some use cases, we want to use an ML algorithm to recommend the next-best-action. In order to do this, the system needs to be able to deploy production models. The infrastructure required to enable this capability includes a serving engine, logging and monitoring, and an API through which to access the model.
Business Rules
In other use cases, a model is not required, or even desired. Typically, a predetermined default action is needed on part of the population to set a baseline, and a random selector is needed for experimentation purposes. In other cases, a predetermined set of rules is sufficient to perform the recommendation.
In this section, we have touched on some of the topics, but a more comprehensive look at machine learning and MLOps will be conducted in part four of this series.
Orchestration
We have built out the capability to create the combined context and to run it through an ML model or through business rules, but we also need the ability to orchestrate this process.
Exclusions and Action Eligibility
Before the recommender determines which option to select from a pool of possible actions, we may need to exclude some customers and/or actions from the process.
These exclusions may be driven by the organisation, but can also be driven by the customer. For example, customers who wish to opt-out of automated decisioning should have their requests go through fixed business rules rather than an AI algorithm. This type of feature is an important aspect in the enablement of a customer’s Autonomy, which is another one of the Australian AI Ethics principles.
There are also scenarios where not all actions may be relevant, or the organisation may wish to apply rules about when some actions should not be presented. For instance, if we do not have an email address for a customer, then an action to send an email would not be a valid option. A more complex example is when regulatory requirements require that marketing messages be limited in terms of contact frequency. In this case, the system needs to be able to track and check that the contact frequency limit had not been exceeded.
Experimentation
More than simply calling an ML model or business rule set, we also want the ability to choose between multiple recommenders and also allocate the traffic volumes. We achieve this capability through configurable experiments that have mappings to the recommendation method and traffic allocations.
This experimentation capability then enables features such as:
- Champion-challenger models
- Uplift measurement
- Automated experimentation through contextual bandits
Here we have introduced the second API abstraction layer. While the first layer allows for the enrichment step before recommendation, this second layer allows the routing of traffic to different methods of making recommendations. For machine learning methods, this requires only that the ML algorithms expose an API that can be called using the joined online and offline context. This decoupling means that modern ML deployment systems that are compatible with this requirement can be used for this component.
We have now built out the following components in our diagram which represents a minimal architecture real-time next-best-action recommendation with data enrichment, experimentation, and machine learning.
Summary
In this post, we explored step two in our next-best-action architecture build, looking at the challenges to enabling data access and the two layer API design that enables the system to meet each of the requirements
In our next post, we dive deeper into the ML component of the architecture and look at how the deployment design pattern for continuous intelligence systems differs from those used in traditional ML.