
We examine how experimentation platforms used by search engine and social media companies have been designed to handle a range of experimentation issues that occur at scale.
While A/B testing is commonly used by web companies, large search engine and social media companies tend to have much larger experimentation programs, which require experimentation platforms that can handle a range of experimentation issues that occur at scale. Experimentation at this level of scaling needs to have high sensitivity, a 0.1% change in the certain metric can correspond to a revenue change of over $1M per year.
In this blog post, we discuss some examples of how their experimentation platforms have been designed to meet these requirements.
Each example addresses the same basic problem, which has the following features:
- Online experiments are performed on a website with live traffic. These experiments are designed to optimise parameter settings for various modular components of the website.
- There is a limited amount of traffic that can be allocated to these experiments.
- There are many (e.g. hundreds per day) experiments that run concurrently. These experiments are run by different teams, and it is possible for experiments to interfere with each other.
Overlapping Experiment Infrastructure (Google)
The experimentation platform used by Google [1] is motivated by their ‘more, better, faster’ design principle: they wanted to increase the number and diversity of simultaneous experiments (more), using a robust experimental design (better) with quick iteration (faster). On Google’s search engine, each search query request has a cookie associated with it, which is typically used as the experiment unit. Random assignment of experiment units is done using a cookie mod. For example, each cookie gets a numeric representation, then calculate modulo 1000 of that number. All cookies with the same mod are then grouped together and assigned the same treatment. A set of cookie mod IDs is called a ’layer’.
Before 2007, the experiment design followed a simple approach where each cookie could belong to at most one experiment, to ensure that experiments could not interfere with each other by experimenting on the same cookie. This is the single-layer approach, with all experiments in the same layer. For example, consider two experiments in the same layer (illustrated below), one controlling the highlight box colour (default: yellow), and the other controlling whether suggestions are shown (default: on).
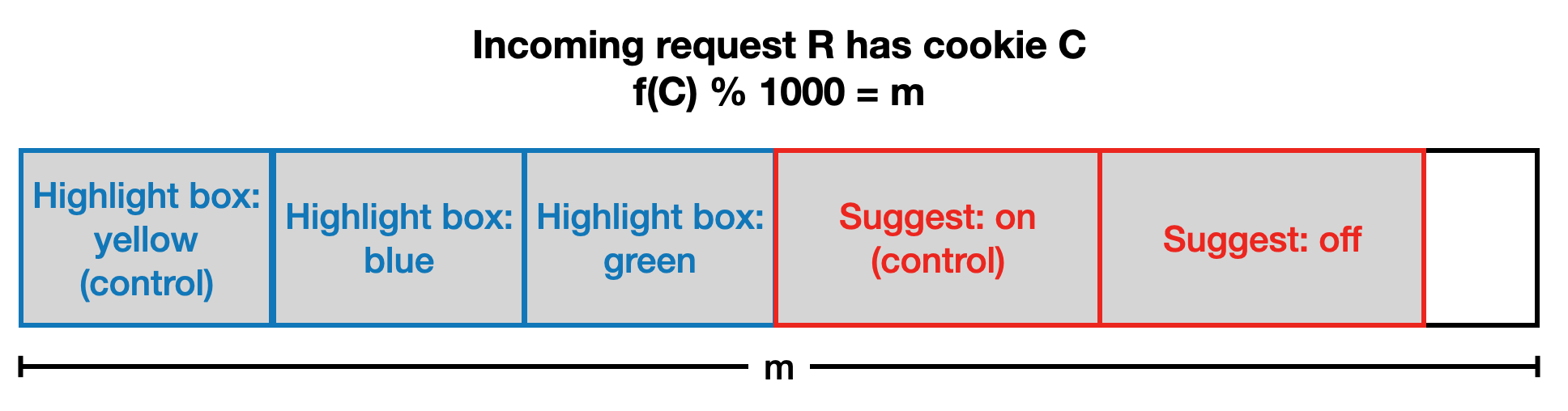
If we draw an imaginary vertical line through the layer, we see that each request is randomly assigned to at most one experiment. While this design is straightforward, it is not scalable, due to the limited number of requests available to each experiment.
For increased scalability, the design was modified to use traffic more efficiently. This was achieved by allowing experiments on independent parameters to run in parallel, depending on some conditions. In the example below, each request is randomly assigned to either the highlight box colour experiment, or to the simultaneous suggest/weather experiments. If they are assigned to the latter, then the request’s country of origin determines whether they are in the suggest experiment (Brazil) or the weather experiment (Japan). These experiments do not interact, because they are run on disjoint populations.
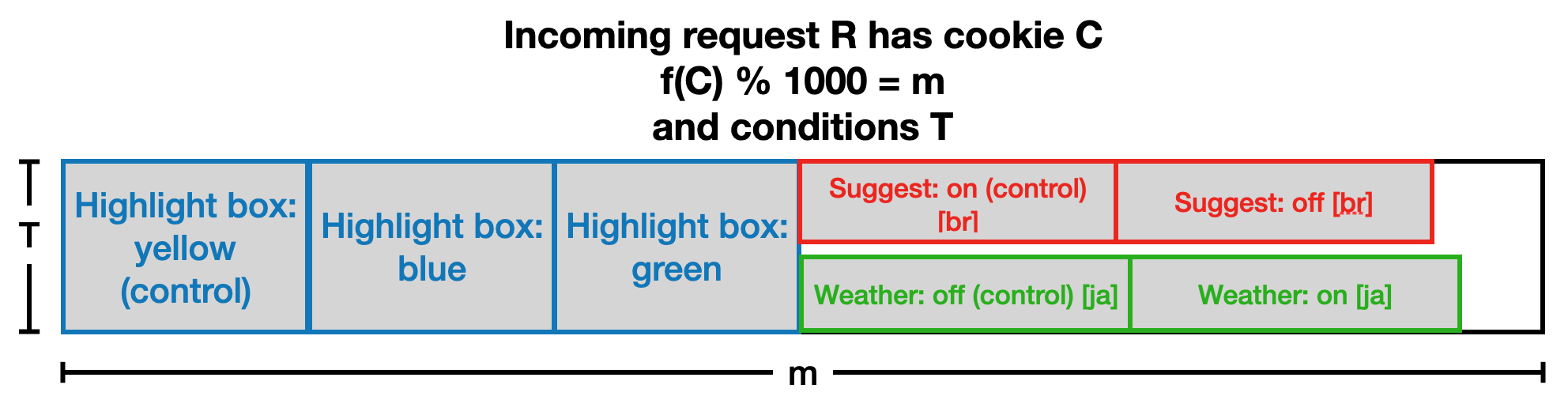
By allowing requests to be in multiple experiments simultaneously, the traffic in this layer can be used more efficiently.
A variation on this design that accounts for interactions between experiments is a multilayer design. In this approach, experiments that can interact with each other are run in the same layer, while experiments on parameters that do not interact are run in separate layers. In the example below, the text and background colours of the top ad are experimented on in the ads layer, because it is possible for them to interact with each other (e.g. blue text on blue background). The experiments are co-ordinated in such a way that this does not occur. The suggestion experiment is run in a separate search layer, because it does not interact with text or background colour.
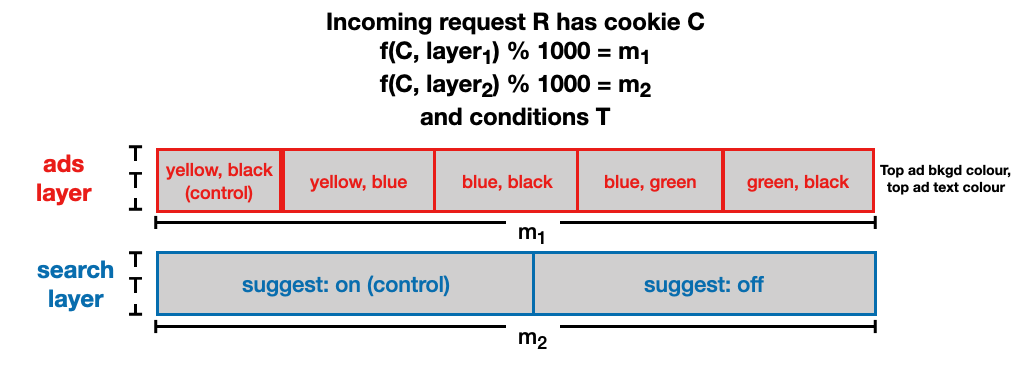
The advantage of this approach is that it allows non-interacting experiments to be run in parallel layers (thus efficiently using the traffic), while interacting experiments are co-ordinated within a single layer.
For additional flexibility, the concept of domains was added to this design, as shown below. With this approach, requests are initially assigned randomly to either overlapping or non-overlapping domains. Requests assigned to the overlapping domain follow the multilayer experiment design, where disjoint populations can also be created using conditions. Requests assigned to the non-overlapping domain follow a single-layer experiment design.
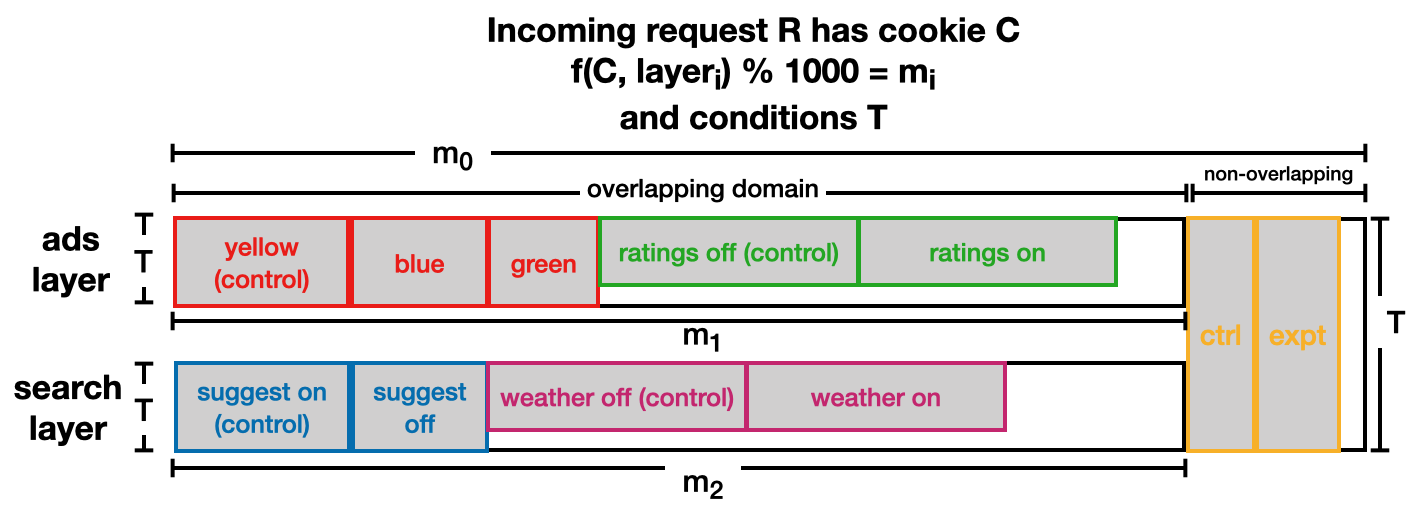
This design is highly flexible, as there can be multiple overlapping domains, and domains nested in other domains. This makes the design highly adaptable to changing experimentation requirements. While these domain and layer concepts might be overly complicated for simple applications, they have been successfully used at Google to enable the level of experimentation flexibility required for their application.
Bing Experimentation System (Microsoft)
Another search engine example is Bing, where multiple concurrent experiments are also required. Microsoft uses the Bing Experimentation System [2], which uses the multilayer design to group related experiments and run independent experiments in parallel, as illustrated below.
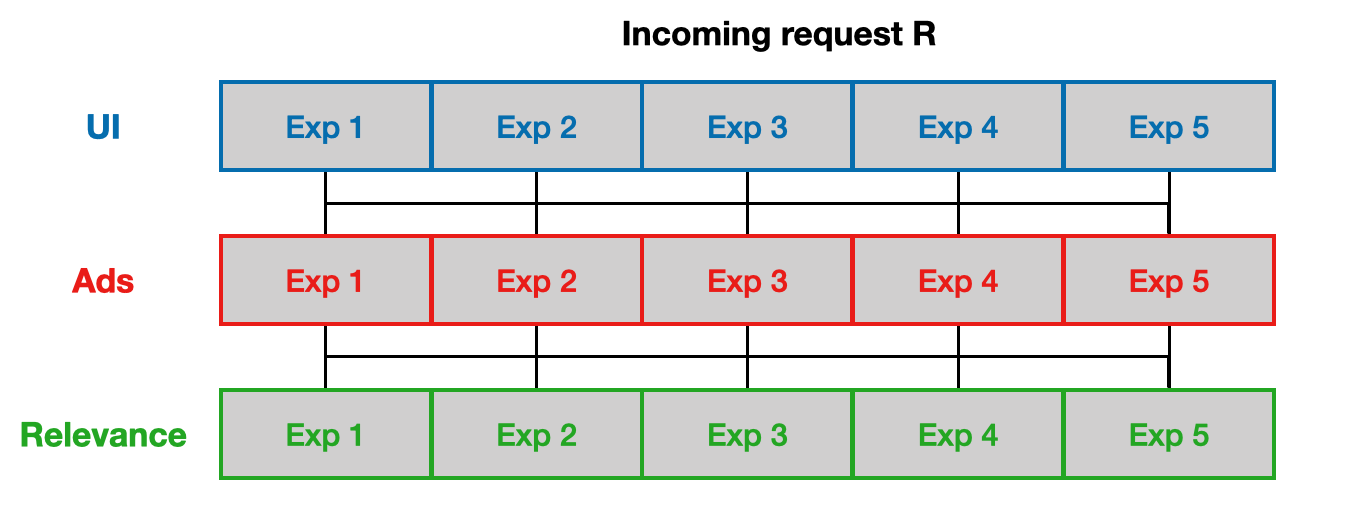
For example, experiments run on the UI can interfere with each other, so these experiments are grouped together in th UI layer. Each request can only belong to one experiment in this layer, but they can also belong to concurrent experiments in the other layers.
The experiment architecture for this system is illustrated below, where a ‘flight’ is Bing’s terminology for a variant exposed to an end user. The three main areas of the architecture are the online infrastructure, experiment management, and offline analysis.
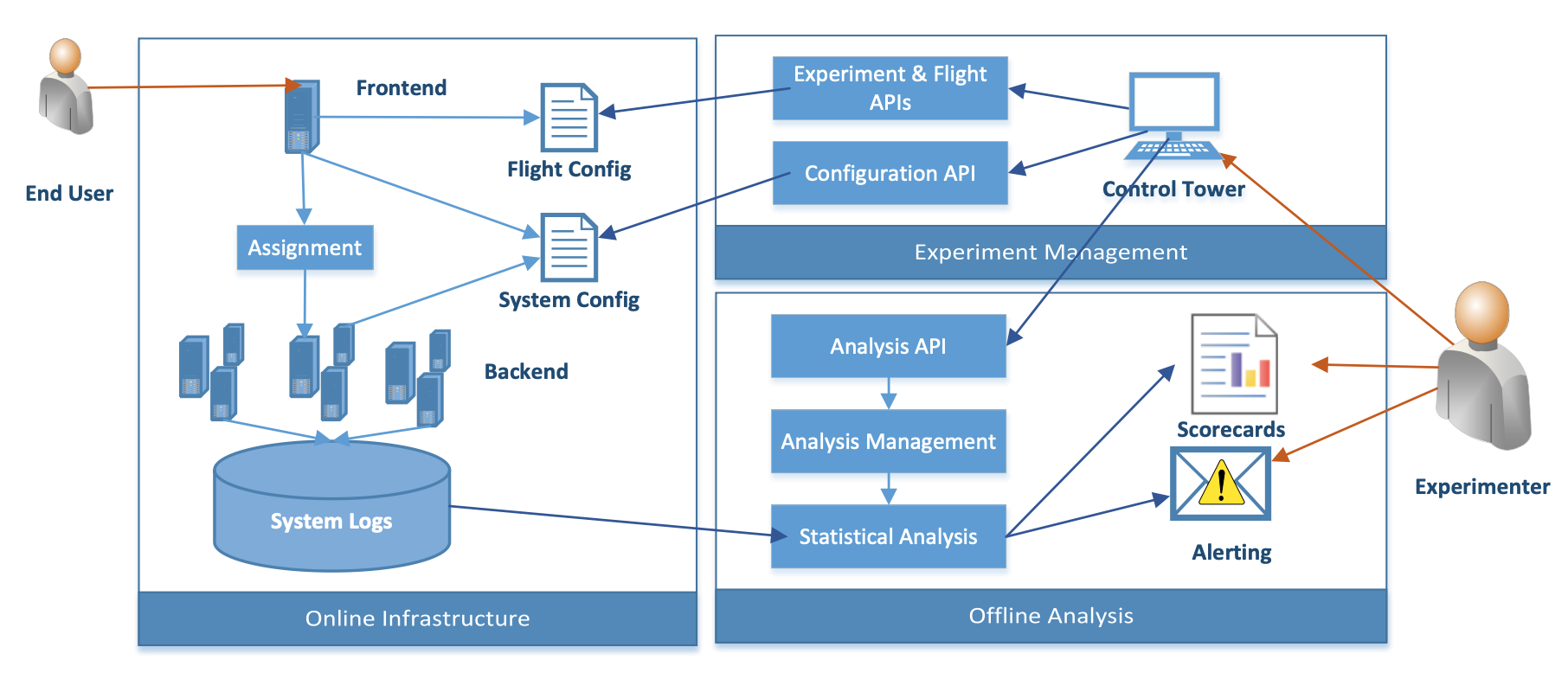
The online infrastructure assigns incoming requests to multiple flights and ensures that each user receives a consistent experience. The experiment configurations are defined by the experimenter in the control tower, which resides in a separate experiment management area. The experiment results and configurations are logged and processed in a separate offline analysis area. There is also an alerting system in place so that experiments that degrade the user experience too much (e.g. long page load times) can be aborted quickly.
Although the the Bing Experimentation System’s default assumption is that experiments do not interact, there is constant monitoring to prevent and detect such interactions. To prevent interactions, experiment configurations must define sets of constraints, to ensure that conflicting experiments do not run together. The configuration management system also automatically detects experiments that are trying to vary the same parameter. If interacting experiments are unavoidable, then mappings are used to create disjoint sets of users for each experiment.
If interacting experiments do manage to slip past these prevention measures, then they must be detected while they are running live. This is done by monitoring all running experiments for potential pairwise interactions on various metrics. This requires running hundreds of thousands of hypothesis tests, with additional algorithms used to identify the ones that are most likely to be true positives. If a pair of interacting experiments is detected, then the experiment owners are alerted.
As with Google, the Bing Experimentation System has allowed Microsoft to massively scale up their experimentation program.
XLNT (LinkedIn)
LinkedIn’s experimentation platform is called XLNT [3], and was designed according to these design principles:
- Scalability. The platform must be able to handle a large number of concurrent experiments, with a large volume of data per experiment.
- Incorporating Existing Practices. The platform must be compatible with existing A/B testing practices, including personalised user experiences that LinkedIn commonly uses.
- Engineering Integration. The platform must be well integrated with the existing engineering infrastructure. A platform that works for one organisation probably won’t work for a different organisation, due to different structures and constraints.
- Flexibility. Different teams have different experimentation requirements, and the platform must be able to handle this level of customisation.
- Usability. To enable experimenation for everyone in the organisation, the platform must provide an intuitive user interface for designing, deploying, and analysing experiments.
The XLNT platform architecture built to meet these requirements is shown below. Experimenters access the platform via a user interface, which resides in the corporate fabric. From here, they can access the service layer in the production fabric. This is where they can define experiments and query member attributes. Experiments are tested and deployed from this layer. Separate from the service layer is an application layer, which runs experiments and logs experiment results. Automated reports are also generated and provided back to the user interface.
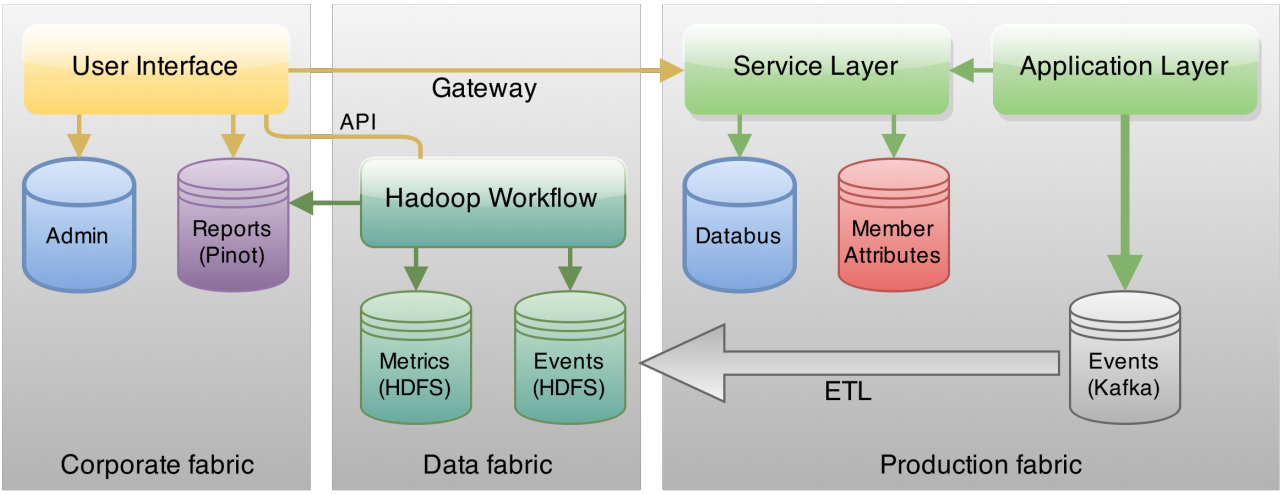
Because LinkedIn has an emphasis on personalised user experiences, they log a wide range of user attributes to achieve this. There are three categories of these attributes:
- Built-In Member Attributes. This is the default set of over 40 member attributes, which can be static (e.g. member’s country) or dynamic (e.g. last login date).
- Customised Member Attributes. If additional member attributes are required for a particular experiment, they can be uploaded regularly or as one-off jobs from external data sources.
- Real-time Attributes. These are attributes that are only available at runtime (e.g. browser type or mobile device).
This hybrid of centralised and decentralised management of attributes enables consistency on a core set of attributes, while maintaining flexibility on experiment-specific attributes.
A similar approach is taken with respect to reporting metrics. LinkedIn has many products with product-specific metrics, there are over 1000 experiment metrics to be computed. These metrics are grouped into three tiers: 1) Company wide 2) Product Specific 3) Feature Specific. Tier 1 metrics are owned and maintained by a central team, whereas Tier 2 and 3 metrics are owned by the relevant teams and only computed by the central team. Tier 1 and 2 metrics are computed daily, while tier 3 metrics are only computed as needed.
Interactions between experiments
In terms of interactions between experiments, LinkedIn (like Microsoft) takes the position that experiments are assumed to be independent by default, which allows them to be run in parallel without interfering with each other. In most cases, this assumption is valid.
However, there are certain sitations where this assumption does not hold. For example, one experiment may toggle whether a module is shown or not, and another experiment may vary the number of articles shown by this module. Clearly, the latter experiment depends on the former. In this situation, LinkedIn uses a gating key, where the latter experiment is only activated if the former experiment is toggled to ‘on’. This gating key concept can also be used to set up multiple experiments with disjoint traffic. By creating a gating key with N variants, each variant acts as a bucket sending traffic to only one of the N experiments.
LinkedIn also uses factorial design in their experiments, so that any potential interaction effects can be analysed. If there are no interaction effects, then the experiments can be analysed separately while each efficiently makes use of the full traffic.
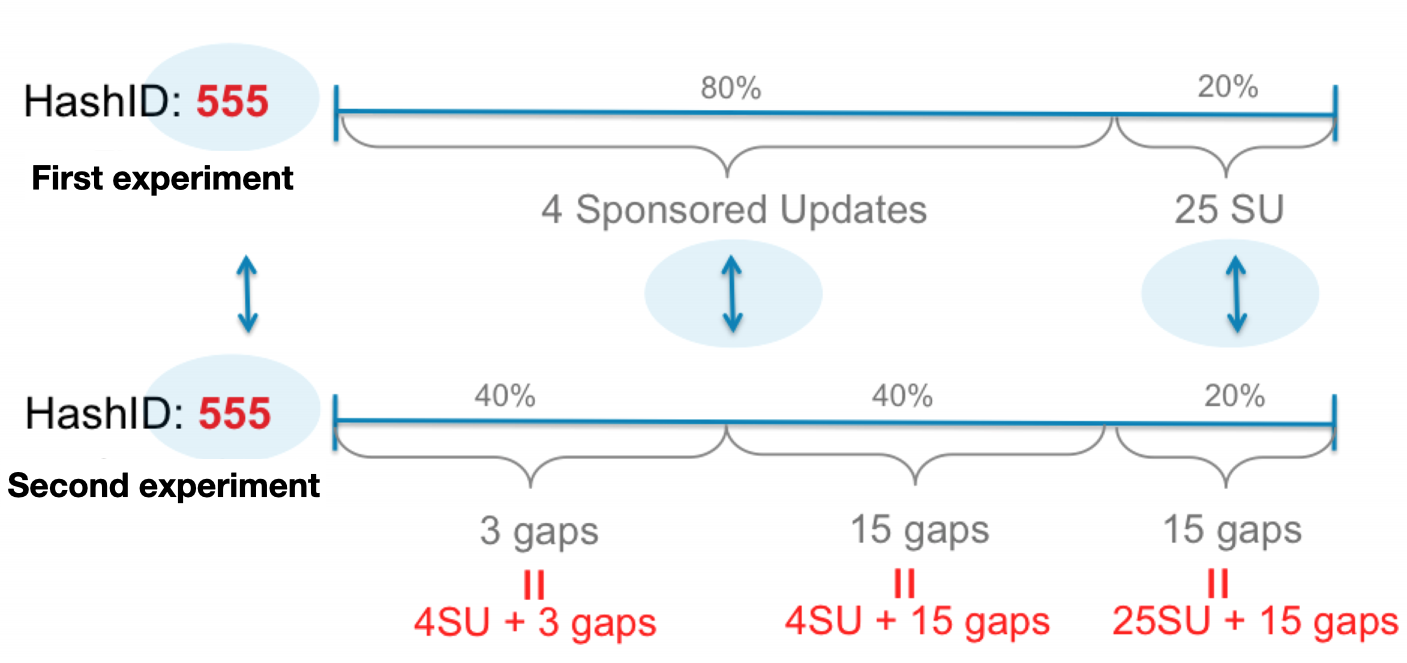
Certain experiments can also interact on a certain combinations of factors, but not all. For example, there may be one experiment testing the maximum number of sponsored updates to include in a newsfeed, while another experiment varies the size of the gap between sponsored updates. Some combinations produced by this pair of experiments should never be tested (e.g. 25 sponsored updates with a gap of 3 organic updates between each one). The experiments can be aligned in such a way that only good combinations are tested, as illustrated below.
Experiment unit considerations
Another consideration for LinkedIn is that users can be members (logged in) or guests (not logged in), and they can transition between these states. While members logging in and out is less of a concern, guest users becoming members is an important onboarding use case to consider. To achieve continuity between these states, browser IDs and member IDs are both tracked by the relevant experiments.
As a social network, experimentation at LinkedIn has additional challenges. A key assumption made in experimentation is the ‘Stable Unit Treatment Value Assumption’ (SUTVA), which states that user behaviour depends on their own treatment only, and not on the treatment of others. Due to the connections between LinkedIn users, it is easy for this assumption to be violated. For example, introducing video chat is likely to not just affect the behaviour of the targeted user, but the behaviour of the targeted user’s contacts as well. This makes it possible for the effect of an intervention targeting treatment users to spillover and affect control users. LinkedIn’s approach to these network effects is to consider each user’s network connections when assigning them to treatment or control. Users who belong to the same cluster form a single experiment unit, and random allocation to treatment or control is done at the cluster level, rather than the user level.
Summary of key principles
So, what does this tell us about scaling up experimentation? Some common themes emerge when we consider these experimentation platforms together. Firstly, the websites that they run experiments on are highly modular, which makes it easier to isolate independent experiments from each other. This allows them to take an optimistic view with regards to interacting experiments - the default assumption is that most of their experiments do not interact with each other. Nevertheless, there are mechanisms for handling situations where interacting experiments arise, both in terms of preventing from being deployed, and quickly detecting them if they are deployed.
The modular website design carries over into the experimentation platforms themselves, with experiment configuration isolated from application logic. Configuring experiments is simple, requiring minimal technical skills from the end user.
These experimentation platforms share an emphasis on scalability, as they anticipate the number and size of their experiments to increase. There is also an expectation that the experimentation platforms need to adapt to the diverse requirements of multiple teams running experiments on the available traffic. This is balanced by the need for automation of basic reporting, to ensure that the analysis is consistent and robust.
The experimentation platforms must also carefully balance the allocation of their limited traffic (even Google) across the large number of experiments. This requires careful experiment design that is specific to the particular application.
In summary, while there are useful concepts that can be reused in other organisations looking to scale up their experimentation programs, every implementation needs to be adapted to the relevant requirements. Specifically, most organisations do not need experimentation platforms as complex as the ones used by Google, Microsoft, or LinkedIn. At Ambiata, we have designed the Atmosphere platform to solve many of these experimentation issues, with a particular focus on continuous intelligence algorithms. We will discuss how Atmosphere works in more detail in an upcoming blog post.